
Bienvenido a TeideHPC#
Visite nuestra web para encontrar más información sobre la infraestructura https://teidehpc.iter.es o envíenos un mail a teidehpc@iter.es.

La infraestructura Teide HPC (High Performance Computing) constituye una pieza fundamental del proyecto ALiX para la puesta en marcha de infraestructuras orientadas a la creación de un tejido industrial en torno a las Tecnología de la Información y la Comunicación (TICs) en Tenerife.
El superordenador Teide, es uno de los más potente de España, ofrece a investigadores, empresas del Parque Tecnológico y Científico de Tenerife, y a la Universidad de La Laguna, un medio de alta capacidad de proceso, para mejorar y ampliar el alcance tanto nacional como internacional de las investigaciones. Además está presente en la lista top500 de los supercomputadores más potentes del mundo ocupando el puesto 138 de la lista de noviembre de 2013.
El superordenador Teide es una infraestructura de computación de altas prestaciones de propósito general. Gestionado en el ITER, el superordenador Teide está alojado en datacenter D-ALiX y provisto de infraestructura eléctrica y de frío de alta disponibilidad, y de conectividad a internet de alta velocidad.
Descripción del cluster TeideHPC#
El siguiente diagrama describe de manera muy sencilla cómo está estructurado el cluster.
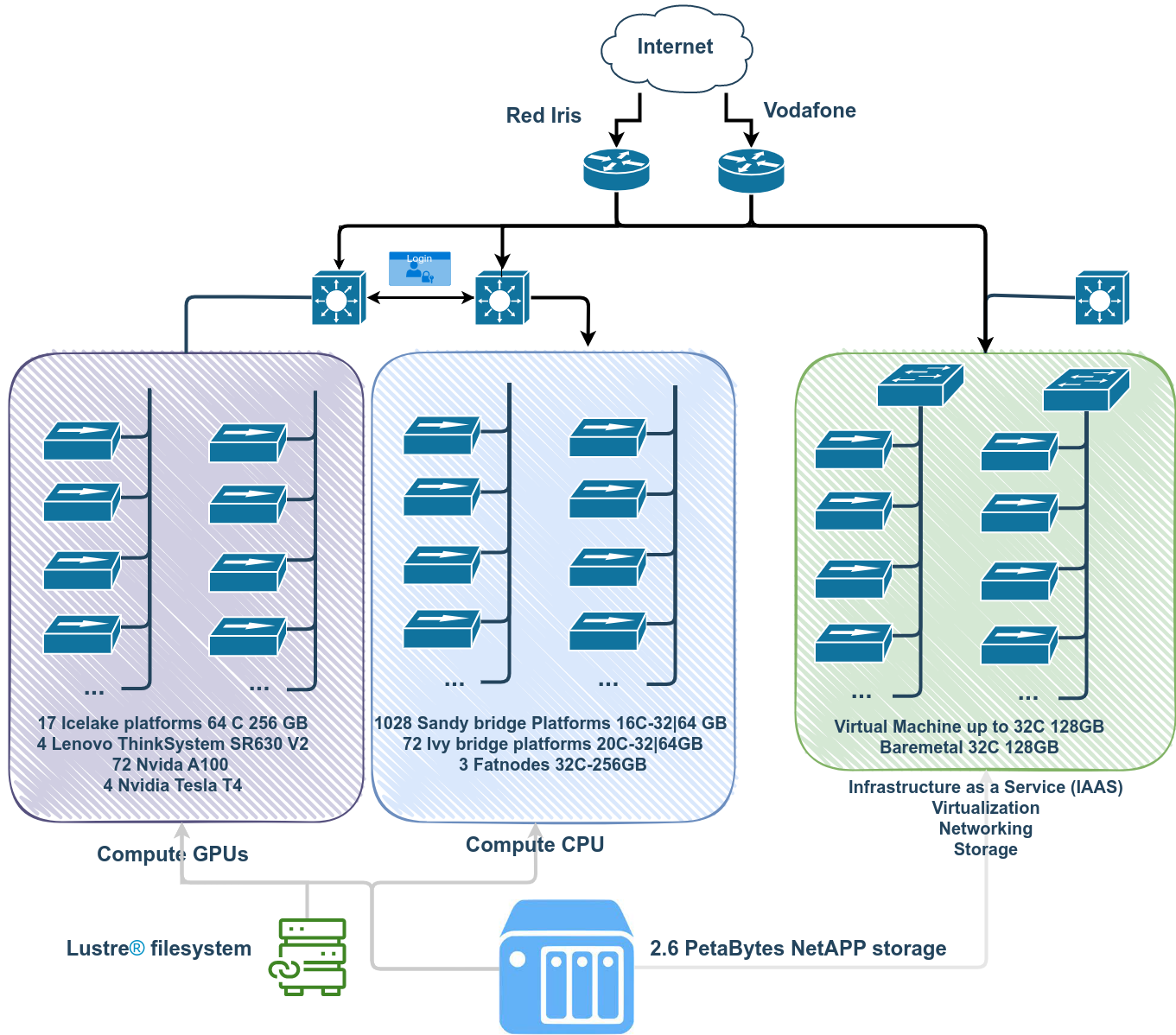
Nodos de cómputo.#
TeideHPC tiene los siguientes plataformas de cómputo.
| Type | Qantity | Platform | Processors | Cores | Memory | # GPUs |
|---|---|---|---|---|---|---|
| CPU | >500 | Sandy bridge | 2 X Intel Xeon E5-2670 | 16 | 32-64GB | - |
| CPU | 72 | Ivy bridge | 2 X Intel Xeon E5-2670v2 | 20 | 32-64GB | - |
| CPU | 3 | Sandy bridge | 2 X Intel Xeon E5-4620 | 32 | 128-256 GB | - |
| GPU | 16 | Icelake | 2 X Intel Xeon Gold 6338 32C | 64 | 256 GB | 4 Nvidia A100 |
| GPU | 1 | Icelake | 2 X Intel Xeon Gold 6338 32C | 64 | 256 GB | 8 Nvidia A100 |
| GPU | 4 | Icelake | 2 X Intel Xeon Gold 6338 32C | 64 | 256 GB | 8 Nvidia T4 |
Almacenamiento#
-
Almacenamiento NetApp con capacidad de 2.6 Peta Bytes, configurada en formato clúster contando con todos los elementos redundados para hacer frente a posibles fallos de hardware, con discos de spare según las best practices, siendo éstos globales.
-
Almacenamiento paralelo Lustre para aplicaciones que requieran un alto número de operaciones de E/S.
Red#
Teide-HPC dispone de una topología de red donde se definen cuatro redes de propósito específico:
- Red dedicada de almacenamiento.
- Red dedicada de gestión.
- Red out of band.
- Red de baja latencia Infiniband EDR a 100Gbps para cómputo.
Como medidas de seguridad TeideHPC dispone de túneles IPSec, conexiones VPN y la posibilidad de establecer VLANs privadas para sus clientes.
Conectividad#
TeideHPC se conecta a internet a través de la red académica y de investigación española, RedIris, mediante un enlace de 10 Gb. También dispone de conectividad a través del proyecto Alix mediante un operador de internet nacional.
Para realizar transferencias de datos, se dispone de nodos de transferencia que permiten copiar grandes cantidades de datos al espacio de usuario accediendo directamente a la red troncal de datos.
Guías de usuario ↵
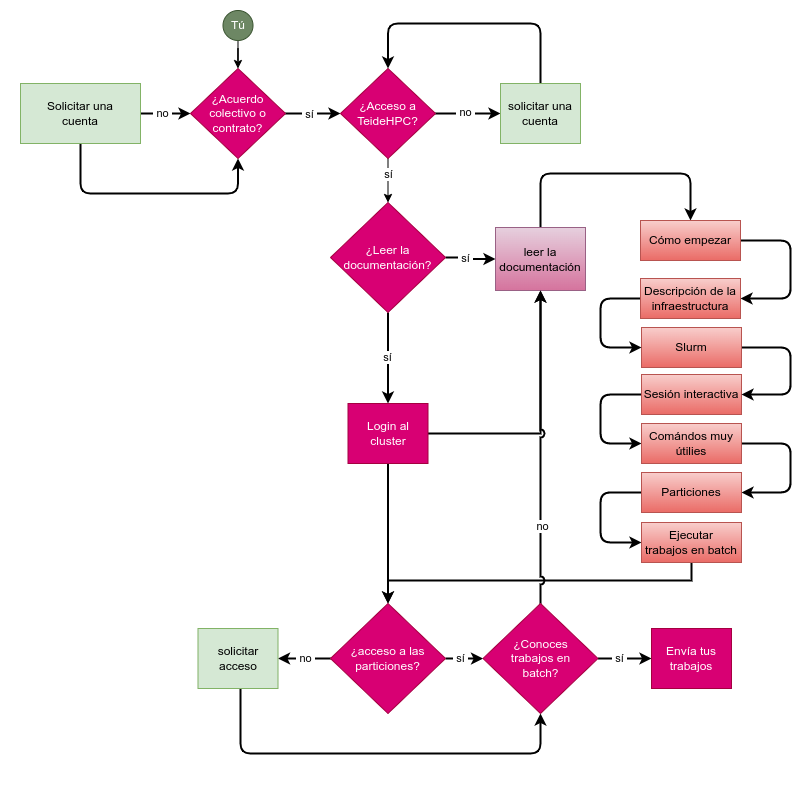
Cómo empezar en TeideHPC#
Esta página lo guiará brevemente a la documentación. Si sigue los pasos a continuación, debería tener una buena idea sobre los aspectos más importantes del clúster TeideHPC.
1. Consigue una cuenta TeideHPC.
Si tu entidad tiene firmado un convenio con nosotros, obtén una cuenta TeideHPC enviando un correo electrónico a soporte@hpc.iter.es informándonos quién es el responsable del departamento o entidad a la que perteneces.
Si eres un investigador o una empresa interesada en utilizar nuestros servicios, pregúntanos.
2. Envíanos una clave pública GPG.
Recibirá sus credenciales de VPN cifradas con su clave pública GPG. Sólo necesitará descifrarlas y conectarse a nuestra VPN.
3. Cambie su contraseña de usuario
Después de conectarte por primera vez puede cambiar su contraseña. Éstas tiene una serie de políticas de seguridad que deberá cumplir así como una fecha de caducidad.
4. Antes de comenzar cualquier cálculo serio, eche un vistazo a las opciones de almacenamiento.
¡Tu directorio home en TeideHPC tiene un límite flexible de 5GB! Recomendamos guardar sus datos en el directorio de datos o lustre
5. Descubra la sección de comandos útiles y consejos de uso
Hay bastantes comandos útiles y consejos de uso que pueden facilitar su vida en el clúster.
6. Antes de enviar un trabajo, recomendamos documentarse sobre los siguientes aspectos":
- Descripción del cluster
- Gestor de trabajos Slurm
- Particiones todas las particiones tienen límites de tiempo diferente.
- Cómo se carga el software
- Sesiones interactivas
- Cómo usar las GPU
- Ejecuciones multinodo (MPI)
7. Familiarizarse con los trabajos en batch
Eche un vistazo a la seccíón Cómo ejecutar trabajos en batch
8. ¡No malgastes!. Usa los nodos y las GPU eficientemente.
Estudia la eficiencia de tus trabajos con slurm o indícanos el número de trabajo, hora de inicio y finalización, así como el nombre de los nodos sobre los que se ejecutó y te enviaremos unas gráficas donde podrás ver el rendimiento del mismo.
9. ¿Necesita Computación en la nube, IaaS (Infraestructura como servicio), virtualización, almacenamiento, red privada o servidores?
Escríbenos a support@hpc.iter.es
10. Cualquier otra cuestión, ayuda o asesoramiento técnico?
Escríbenos a support@hpc.iter.es
Flujo de trabajo recomendado en TeideHPC.#
Guías de transición ↵
Guía de transición a Rocky 8.#
Con motivo de la llegada de las GPU al centro de supercomputación TeideHPC se ha introducido una versión nueva del sistema operativo que usan tanto los nodos de cómputo, GPU y nodos de login. Todo el cluster relacionado con Centos 6 y Centos 7 estarán al final de vida en pocos meses.
Por otra parte, se ha creado un nuevo cluster llamado AnagaGPU y se han realizado algunos cambios en el cluster TeideHPC, así como en el software, por lo que si ya ha ejecutado trabajos en TeideHPC deberá realizar ajustes en su flujo de trabajo.
Resumiendo, estos son los cambios más significativos a nivel de Sistema Operativo, acceso, software, slurm.
Sistema Operativo y nodos de login#
- Cada cluster (TeideHPC y AnagaGPU) tiene su propia IP de acceso.
- El sistema operativo de ambos cluster y los nuevos nodos es Rocky 8.
- Existen 4 nuevos nodos de login dispuestos en alta disponibilidad (HA) mediante 2 IPs de acceso.
- La asignación de nodo de login durante el acceso es aleatoria y va en función del número de usuarios.
Software#
-
El cambio en el sistema operativo significa que la mayoría del software de los usuarios basado en Centos 6 o CentOS 7 no funcionará y ha de ser recompilado.
-
Se deja de usar la herramienta de modules TCL (Centos 6) en virtud de Lmod.
-
El software instalado pasa a estar organizado mediante una nomenclatura plana
-
Cada tipo de nodos tiene instalado y compilado el software específico para cada arquitectura de nodos. Esto quiere decir:
El software instalado depende de la arquitectura de los nodos
- Básicamente hay 2 arquitecturas: icelake (nodos con GPUs) y sandybrige(nodos de CPU).
- Mira la descripción del cluster en la página principal así cómo la página "Cómo solicitar recursos de GPU y cómputo".
Cada cluster tiene su propio software
Para ver el software disponible en cada cluster debe ingresar a través de las Ip de acceso de cada cluster.
Existen módulos que no dependen de la arquitectura
Slurm#
- La asignación de nodos pasa de ser Modo NO compartido a nodos compartidos.
Esto quiere decir que, al solicitar simplemente 1 nodo de cómputo, no se solicita el nódo completo para el usuario, por lo que se obliga al usuario a realizar una reserva completa de recursos si es lo que se desea.
- Los parámetros por defecto que asigna slurm son:
#SBATCH --node=1
#SBATCH --ntask=1
#SBATCH --ntask-per-node=1
#SBATCH --cpu-per-task=1
#SBATCH --mem=2GB
-
Se ha introducido el uso de una partición nueva para la solicitud de recursos de GPUs.
-
Recomendamos encarecidamente que para ejecutar aplicaciones se use el comando
srun tu_aplicacion. Aquí puedes ver una explicación sencilla de qué implicaciones puede tener usarlo o no usarlo. -
Puedes estudiar la eficiencia de tus trabajos completados con un simple comando.
Repositorio público con ejemplos#
Para facilitar el inicio y acceso a la computación HPC en TeideHPC, hemos creado un repositorio público en github donde iremos publicando ejemplos de uso de aplicaciónes.
Te animamos a colaborar en él. https://github.com/hpciter/user_codes
Ended: Guías de transición
Seguridad y VPN ↵
Claves GPG ↵
¿Qué es GPG?#
GNU Privacy Guard (GnuPG o GPG) es una herramienta de cifrado y firmas digitales que implementa el estándar OpenPGP. GnuGPG permite encriptar y firmar tanto datos como comunicaciones (emails por ejemplo). Cuenta con un sistema de gestión de claves versátil, junto con módulos de acceso para todo tipo de directorios de claves públicas. También conocido como GPG, es una herramienta de línea de comandos con funciones para una fácil integración con otras aplicaciones.
GPG cifra los mensajes usando pares de claves individuales asimétricas generadas por los usuarios. Las claves públicas pueden ser compartidas con otros usuarios de muchas maneras, un ejemplo de ello es depositándolas en los servidores de claves.
NOTA: NUNCA COMPARTA SU CLAVE PRIVADA, GUÁRDELA A BUEN RECAUDO Y SÓLO REMITA O PUBLIQUE EN UN SERVIDOR DE CLAVES LA PÚBLICA.
GPG para usuarios linux#
Todas las distribuciones linux incorporan la aplicación por defecto.
Generar una par de claves (pública y privada)#
Se debe contestar a una serie de preguntas en orden para generar la clave pública y privada:
- Key type. RSA-RSA por defecto.
- Expiration time: Tiempo de validez de la clave.
- User data (Real name, email, comment) . Estos datos son usados para identificar la clave en servidores de claves públicas y/o cuando se le envían a otros usuarios
- Password: Contraseña para proteger la clave privada.
Exportar la clave publica#
Importar una clave publica#
Listar las claves públicas importadas con el siguiente comando:
Encriptar archivos con una clave pública importada#
Desencriptar archivos con la clave privada (si es de nuestra propiedad)#
Otros links utiles sobre gpg#
¿ Qué es GPG ?#
Ver descripción aquí
GPG para usuarios windows#
Existen varias aplicaciones bajo el sistema operativo Windows que permiten generar un par de claves gpg. Entre las más conocidas está Gnu4win y su módulo [Kleopatra]. La aplicación Gpg4win es un software de encriptación de libre distribución el cual permite el cifrado de ficheros y el envío de documentos a través del correo electrónico utilizando criptografía de clave pública para el cifrado de datos y firmas digitales.
Soporta los estándares de criptografía OpenPGP y S/MIME (X.509).
Gpg4win se compone varios módulos, entre ellos:
- GnuPG : la herramienta de cifrado básico
- Kleopatra : administrador de certificados para OpenPGP y X.509
- GPA : un administrador de certificados alternativa ( GNU ) para OpenPGP y X.509
Instalación de GPG4win#
En la web del proyecto descargar la versión más reciente del software. Abrir el instalador y autorizar los cambios en caso necesario. Seguir los pasos indicados con el botón Siguiente.
![]()
Generar una par de claves (pública y privada)#
Una vez instalado Gpg4win vamos a utilizar el módulo Kleopatra para generar un nuevo par de claves gpg. Para ello desde la pestaña Archivo seleccionamos Nuevo Certificado, lo cual abrirá el asistente de generación de certificados.

Pulsa en Nuevo par de claves GPG
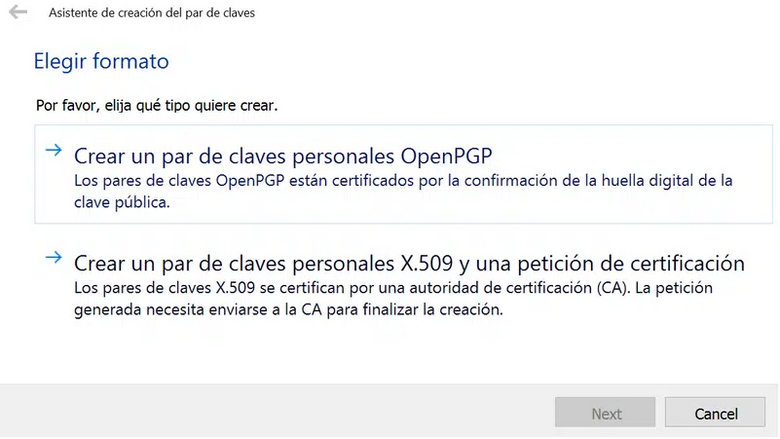
Introducir los datos requeridos
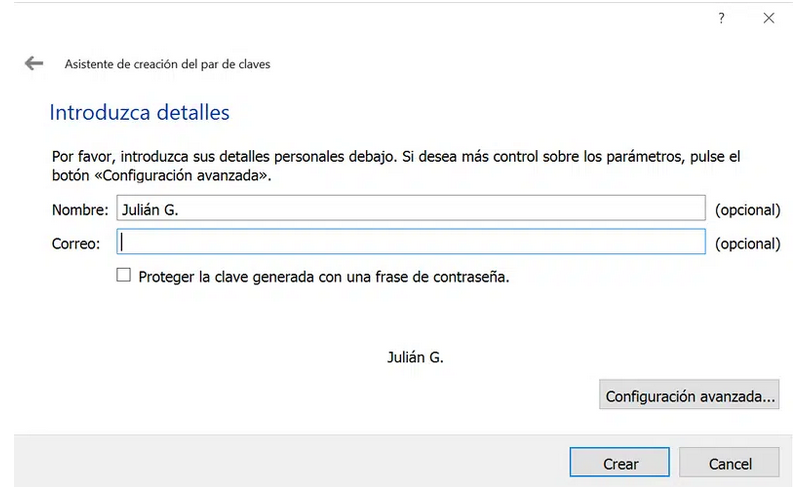
En la pestaña Avanzadas indicar una longitud de clave de 4096 bits y una fecha de caducidad en el desplegable inferior no superior a 2 años.
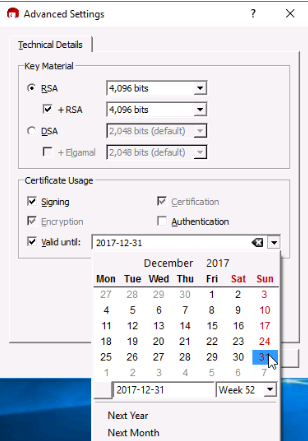
Confirmar los valores introducidos y generar las claves pulsando en Crear.
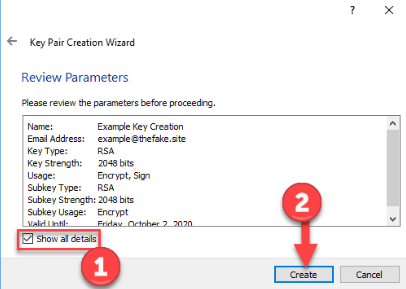
Introducir una contraseña que recuerde para su clave privada. Esta contraseña será la que deba usar para descrifrar los archivos que reciba cifrados con su clave pública.
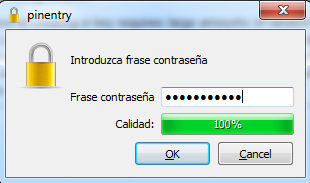
Al pulsar OK verá que su par de claves pública/privadas se han generado correctamente
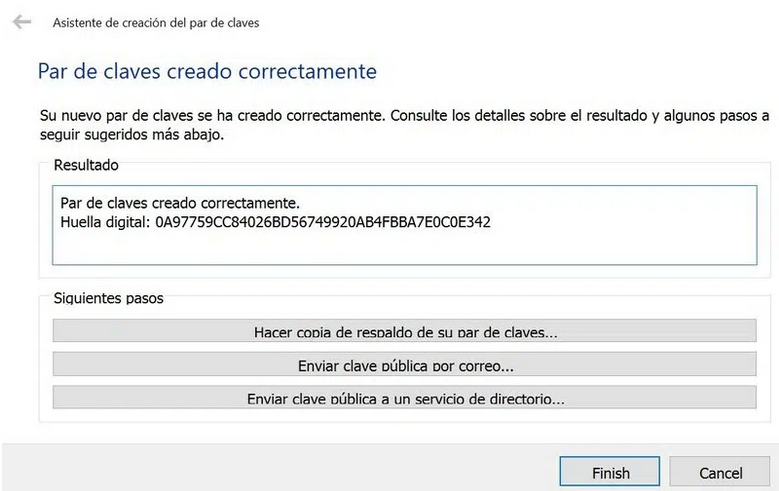
Se puede comprobar que se han creado con éxito el par de claves en la pestaña Certificados.
Exportar la clave pública#
Al exportar la clave pública se genera un fichero de texto que por norma general se almacena con la extensión .asc, que es el que podrá distribuir por correo electrónico o bien publicar en un servidor de claves públicas como REDIRIS y donde cualquier persona la puede descargar.
Obtendrá un fichero de este tipo:
Cifrar ficheros con la clave pública.#
Descifrar ficheros con la clave privada#
Sólo si un archivo .gpg ha sido cifrado con su clave pública y tiene la clave privada, así como su contraseña, podrá descifrar su contenido.
Se puede usar el menú contextual Descifrar y verificar para recuperar el fichero original pulsando con el segundo botón. También es posible realizar esto desde Kleopatra.
Una vez desencriptado este tendrá el mismo nombre sin la extensión gpg.
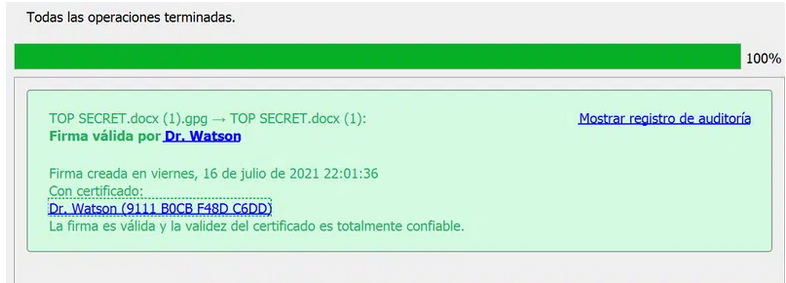
NOTA IMPORTANTE: Si cambia de ordenador o usa uno diferente asegurese de tener su par de claves a buen recaudo. Sin ellas no tendrá la posibilidad de descrifrar el contenido del archivo. Por ello recomendamos realizar un backup del par de claves GPG
¿Qué es GPG?#
GNU Privacy Guard (GnuPG o GPG) es una herramienta de cifrado y firmas digitales que implementa el estándar OpenPGP. GnuGPG permite encriptar y firmar tanto datos como comunicaciones (emails por ejemplo). Cuenta con un sistema de gestión de claves versátil, junto con módulos de acceso para todo tipo de directorios de claves públicas. También conocido como GPG, es una herramienta de línea de comandos con funciones para una fácil integración con otras aplicaciones.
GPG cifra los mensajes usando pares de claves individuales asimétricas generadas por los usuarios. Las claves públicas pueden ser compartidas con otros usuarios de muchas maneras, un ejemplo de ello es depositándolas en los servidores de claves.
NOTA: NUNCA COMPARTA SU CLAVE PRIVADA, GUÁRDELA A BUEN RECAUDO Y SÓLO REMITA O PUBLIQUE EN UN SERVIDOR DE CLAVES LA PÚBLICA.
GPG para usuarios de macOS#
A la hora de instalar gpg en macOS tenemos dos formas:
- Instalar la GPG Suite
- Instalar GPG utilizando el gestor de paquetes Homebrew
Recomendamos instalar gpg a través de Homebrew y utilizarlo a través de la terminal, como por ejemplo, iTerm.
Generar una par de claves (pública y privada)#
Se debe contestar a una serie de preguntas en orden para generar la clave pública y privada:
- Key type. RSA-RSA por defecto.
- Expiration time: Tiempo de validez de la clave.
- User data (Real name, email, comment) . Estos datos son usados para identificar la clave en servidores de claves públicas y/o cuando se le envían a otros usuarios
- Password: Contraseña para proteger la clave privada.
Exportar la clave publica#
Importar una clave publica#
Listar las claves públicas importadas con el siguiente comando:
Encriptar archivos con una clave pública importada#
Desencriptar archivos con la clave privada (si es de nuestra propiedad)#
Otros links utiles sobre gpg#
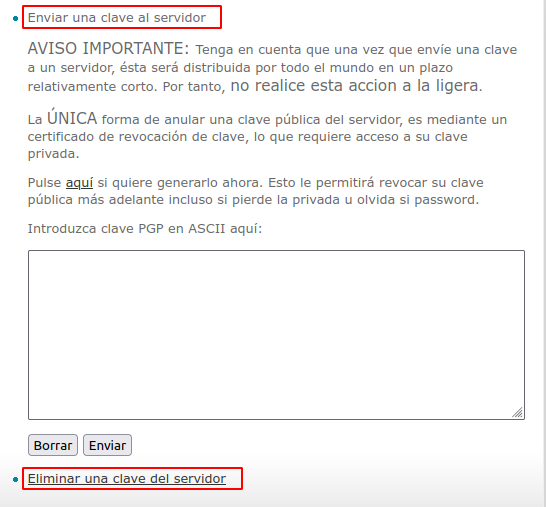
Publicar una clave GPG en un servidor público#
Como se comentaba en apartados anteriores es posible publicar la clave pública en servidores de claves GPG que facilitan el acceso a ellas.
Entre los más conocidos está el servidor de la Rediris.
Este servidor permite tanto consultar claves públicas gpg como publicar las nuestras, así como revocarlas. Estas claves estarán vigentes durante el tiempo que haya dispuesto al generarlas.

Ended: Claves GPG
OpenVPN ↵
OpenVPN para usuarios Linux#
Con el fin de proporcionar un acceso seguro a la infraestructura de TeideHPC todas las comunicaciones serán mediante una red privada virtual (VPN).
Los usuarios recibirán en su momento un email con los ficheros de configuración y las credenciales de acceso cifrados con su cláve pública GPG.
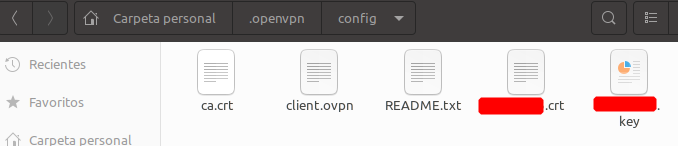
El contenido del mismo es el siguiente:
- Cuatro ficheros que contienen los certificados del cliente.
- Un fichero client.ovpn que contiene los datos de conexión
- Un fichero README.txt con las credenciales de acceso.
Recordamos que las credenciales VPN tienen carácter personal e intransferible y que solo se permite una única conexión simultánea por VPN.
La mayoría de distribuciones actuales de linux traen instalado un cliente de openVPN por defecto. Éste es posible usarlo mediante terminal o bien configurarlo y usarlo mediante interfaz gráfica.
Cómo primer paso descifre y posteriormente descomprima el fichero gpg que se le adjuntó y colóquelo en una carpeta dentro de su /home.
Conexión mediante terminal#
Para conectarse a la VPN sólo tiene que ir a la ruta ~suhome/.openvpn/su_configuración/ y ejecutar:
Conexión mediante interfaz gráfica#
Mostramos a continuación una pequeña guía para la distribución Ubuntu 20.04.
Abra el gestor de redes mediante el acceso en la barra de escritorio o bien teclear en el menú de aplicaciónes Configuración.

Abrimos la configuración de Red y agregamos una nueva conexión VPN:
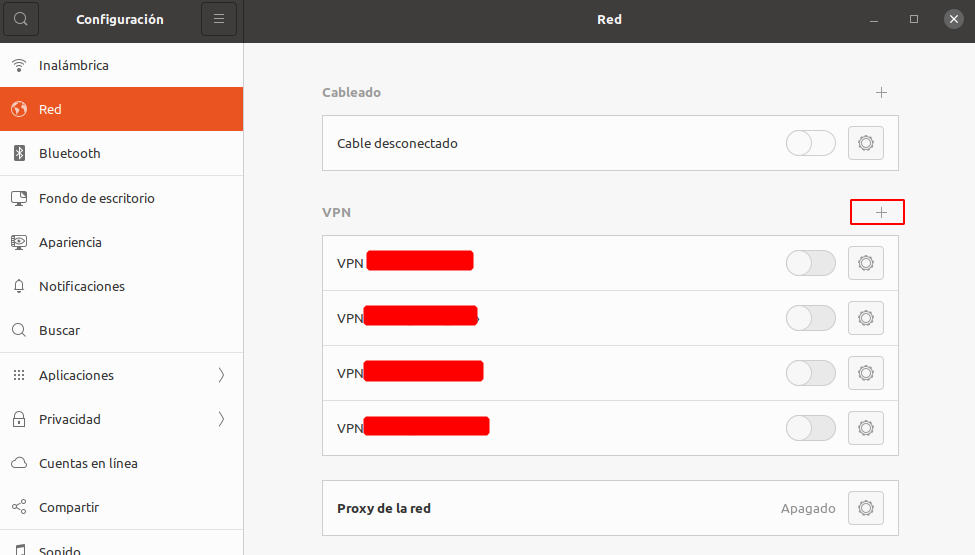
Importamos la configuración desde un archivo
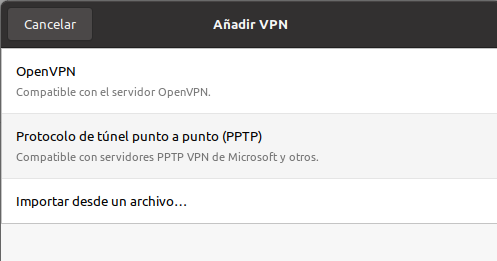
Introducimos nuestro usuario y contraseña
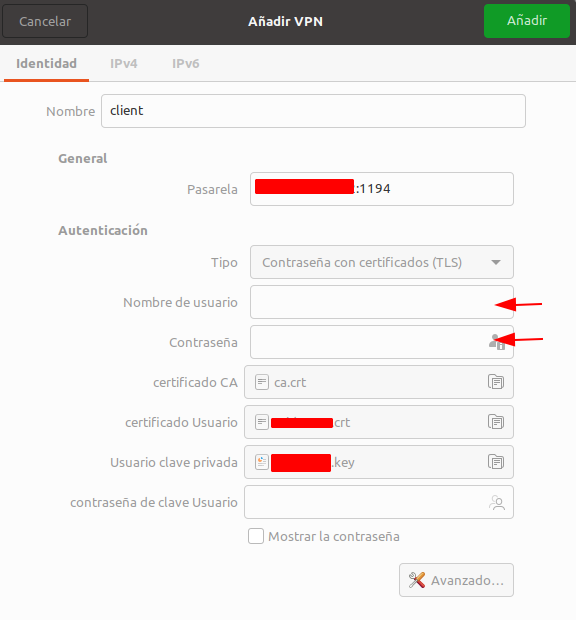
Guardamos la configuración y ya podemos probar a conectarnos a la VPN de TeideHPC.
OpenVPN para usuarios Windows#
Con el fin de proporcionar un acceso seguro a la infraestructura de TeideHPC todas las comunicaciones serán mediante una red privada virtual (VPN).
Los usuarios recibirán en su momento un email con los ficheros de configuración y las credenciales de acceso cifrados con su cláve pública GPG.
El contenido del mismo es el siguiente:
- 4 ficheros que contienen los certificados del cliente.
- 1 fichero client.ovpn que contiene los datos de conexión
- 1 fichero README.txt con las credenciales de acceso.
Recordamos que las claves y ficheros de acceso a la VPN y el usuario y contraseña son personales e intransferibles y sólo permite una conexión simultánea.
Descarga e instalación#
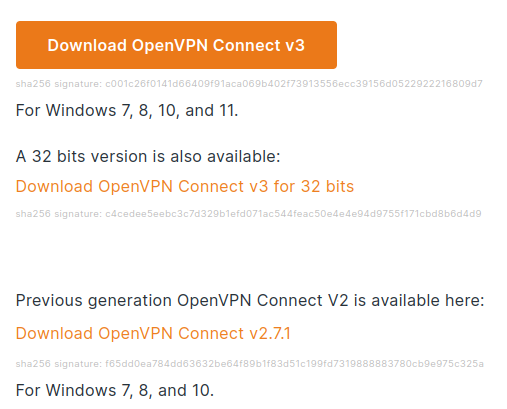
Aunque Windows 10 y Windows 11 dispone de un cliente VPN propio que podría usarse, recomendamos OpenVPN en su versión 3.
Descargar el cliente OpenVPN en el siguiente link.
Ejecutar el archivo descargado y le saldrá el asistente de instalación
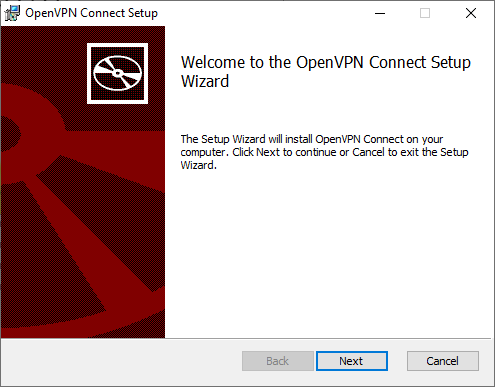
Acepte los términos de uso y siga las instrucciones de instalación:
Acepte la licencia
y finalice la instalación
Con esto ya tendrá instalado el cliente de OpenVPN en su ordenador personal.
![]()
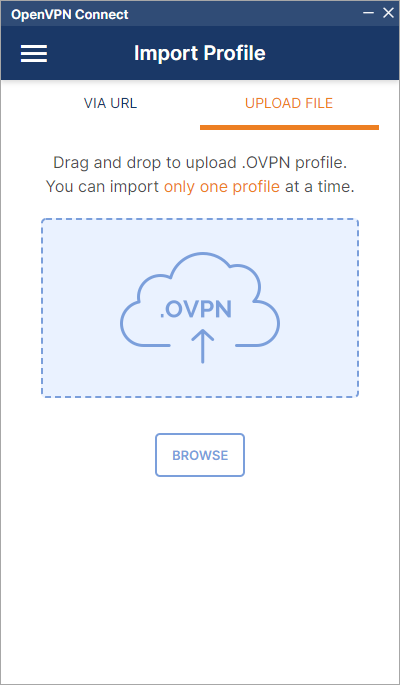
Importar perfil de conexión#
Después de recibir las credenciales cifradas con su clave pública gpg y descifrarlas deberá todos los archivos recibidos en el mismo directorio antes de importar la configuración, por ejemplo:
C:\Users\your_user\VPN\
client_teide-XYYY
├── ca.crt
├── client.ovpn
├── README.txt
├── ta.key
├── teide-XYYY.crt
└── teide-XYYY.key
Conectar a la VPN#
Busque el icono del cliente OpenVPN en el área de notificaciones de windows.
![]()
Una vez abierto podrá configurar la conexión manualmente o lo más sencillo es importar el archivo client.ovpn arrastrando, haciendo doble click sobre él o bien, pulsando el icono BROWSE
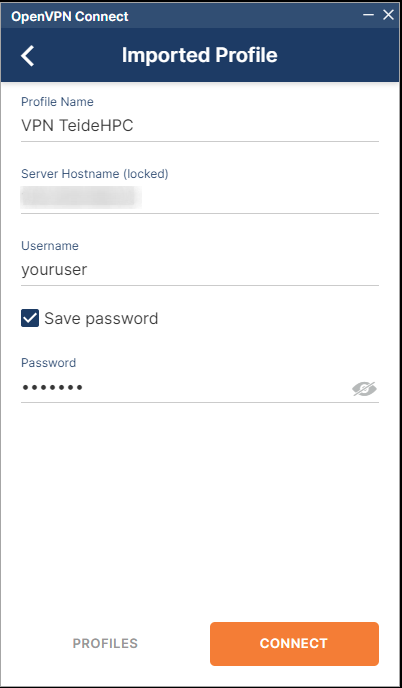
Una vez introducidas las credenciales, el su sistema operativo queda en disposición de acceder a la infraestructura de TeideHPC.
Si su conexión es satisfactoria verá el siguiente estado en la conexión creada.
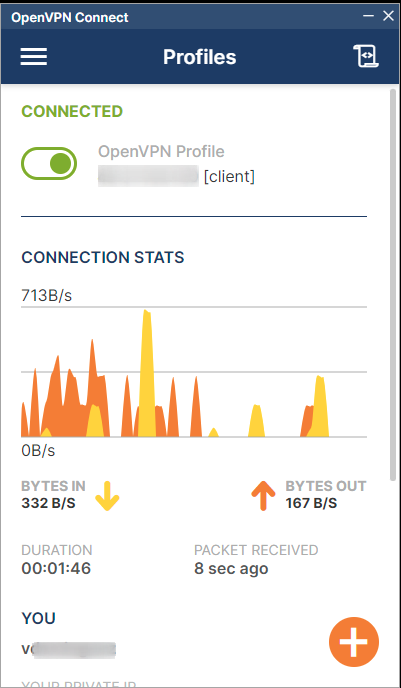
Log de OpenVPN para usuarios Windows.#
En caso de que exista algún problema con la conexión a TeideHPC es importante consultar el log de conexión.
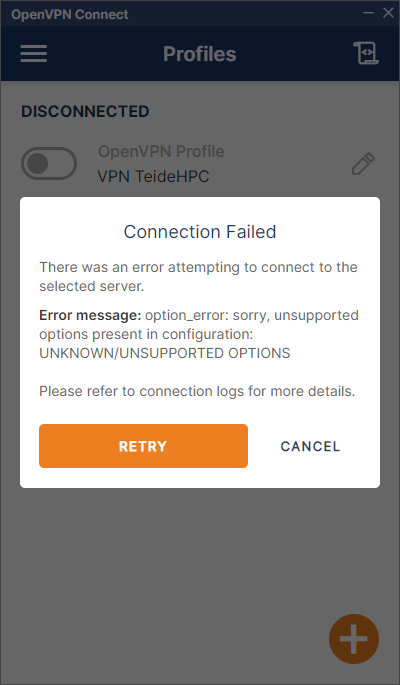
En caso de que la conexión no sea satisfactoria, éste siempre contendrá la información del error.
En caso de que no pueda solucionar el problema por si mismo, siempre le pediremos el log completo, el cual puede exportarlo haciendo click en el sobre.
OpenVPN para macOS#
Para utilizar OpenVPN en macOS no disponemos de un cliente oficial, así que tenemos que utilizar una aplicación de terceros, Tunnelblick, que es la opción más recomendada para abrir una conexión de OpenVPN en macOS.
El presente manual se ha hecho utilizando macOS Ventura y Tunnelblick en su versión estable v3.8.7a.
En este manual no se explica su instalación.
Conectarse a la VPN utilizando Tunnelblick#
Una vez instalado el software lo abrimos para añadir una nueva conexión VPN:
Para añadir una nueva conexión, podemos darle al símbolo "+" que hay en la esquina inferior izquierda:
Tal y como vemos, para crear una nueva conexión tenemos que arrastrar el fichero de configuración al apartado de Configuraciones. En nuestro caso sería el fichero <nombre_usuario>.ovpn. Lo hacemos, arrastramos el fichero de configuración para crear una nueva configuración VPN.
Dependiendo del ordenador en el que estemos trabajando, nos pude interesar crear la conexión únicamente para nuestro usuario o disponible para todos. En este caso, será solo para nuestro usuario, por tanto, "Solo Yo".
Se nos pedirá que introduzcamos la contraseña de usuario (del ordenador) para permitir que haga cambios:
Una vez creada, aparecerá en el recuadro de la izquierda
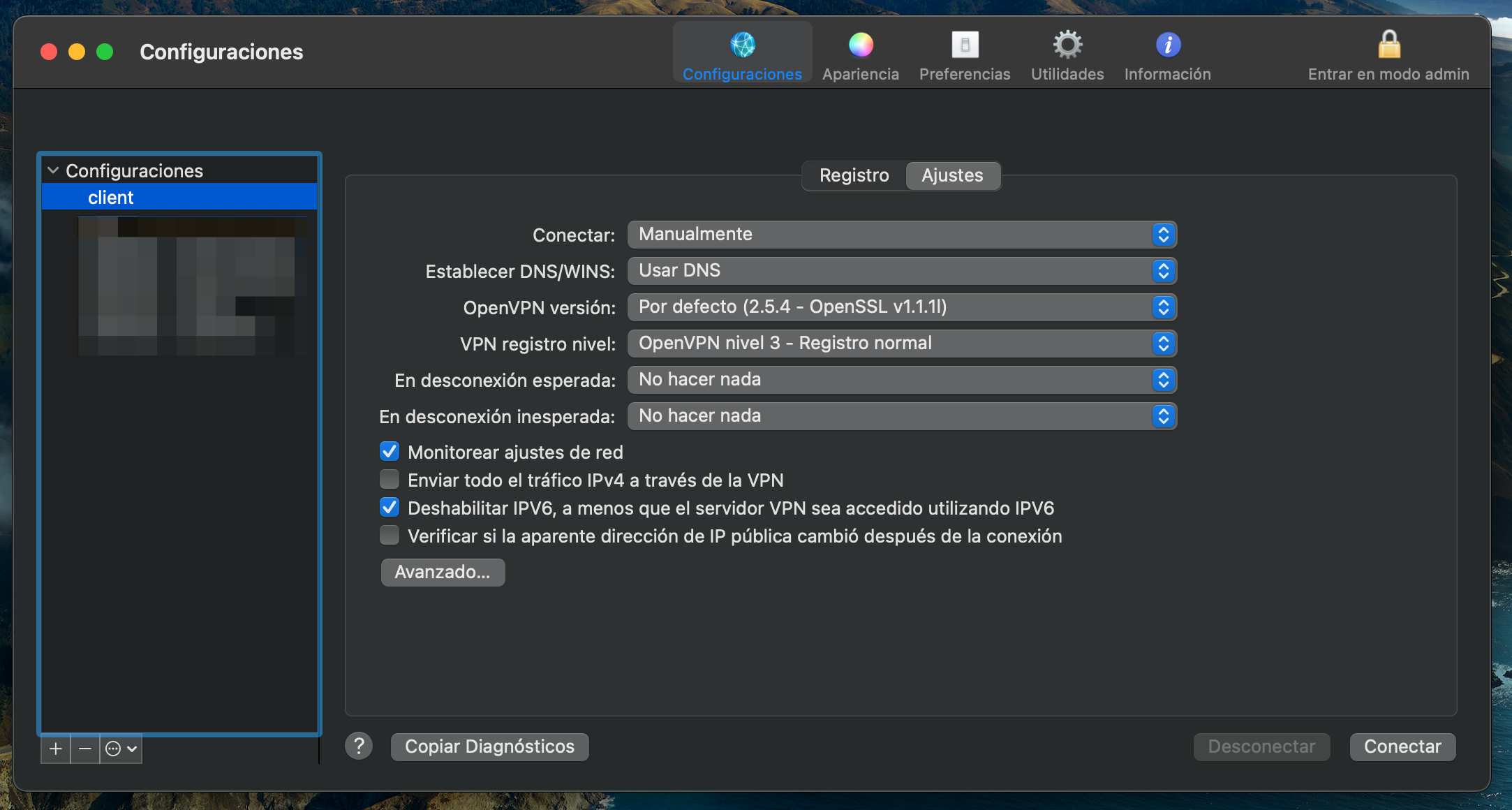
Modificar las opciones avanzadas.
Una vez modificado la opciones avanzadas podemos "Conectar":

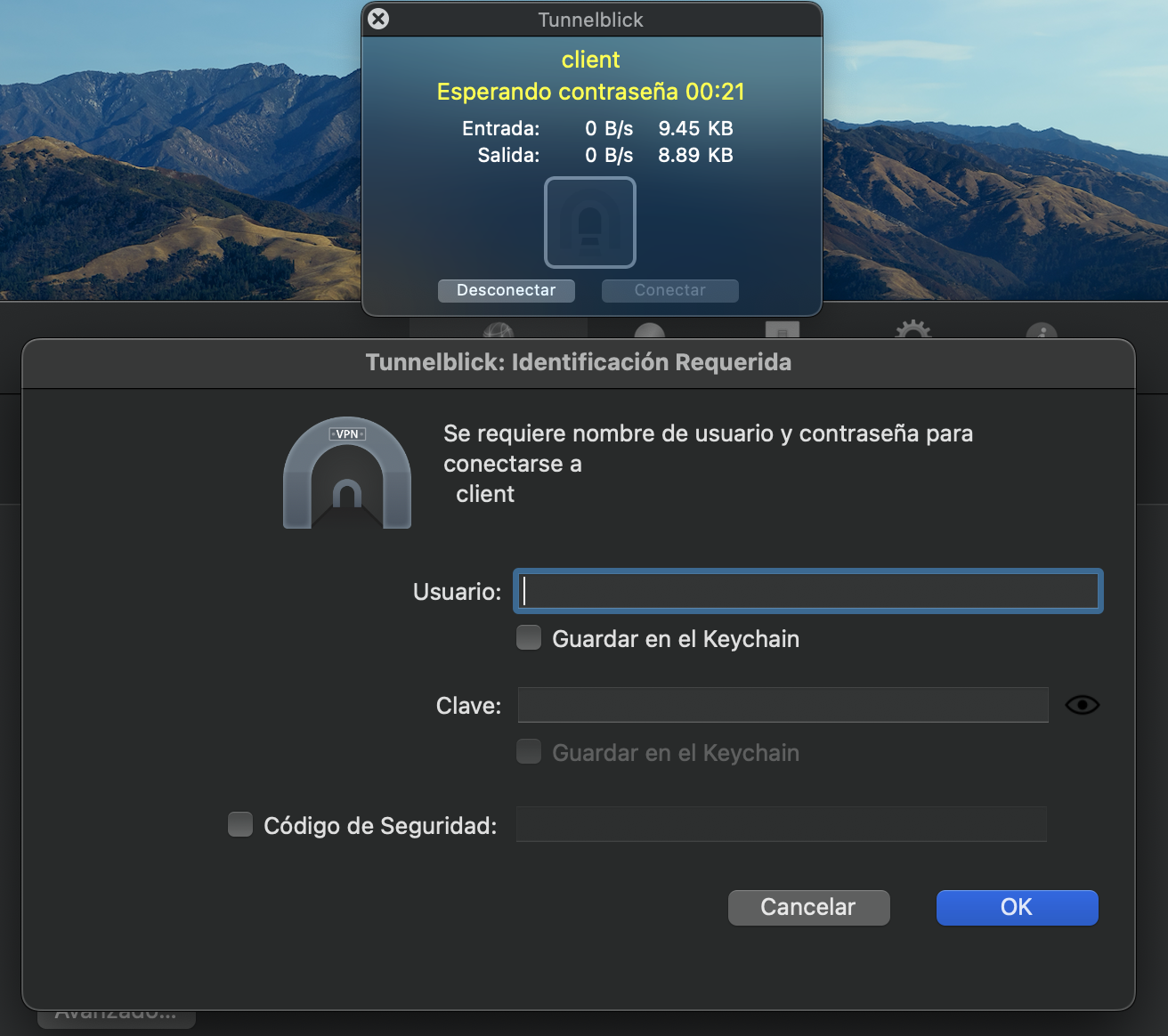
Al hacerlo, nos pedirá que introduzcamos las credenciales de la VPN, es decir, el usuario y contraseña:
Si lo hemos introducido correctamente y todo ha ido bien, nos habremos conectado correctamente:
Una vez conectado a la VPN, podremos conectarnos vía SSH al nodo de login de TeideHPC utilizando la terminal:
Para desconectarnos, podemos hacerlo desde el propio programa o desde el icono del programa que encontramos en la barra superior:
![]()
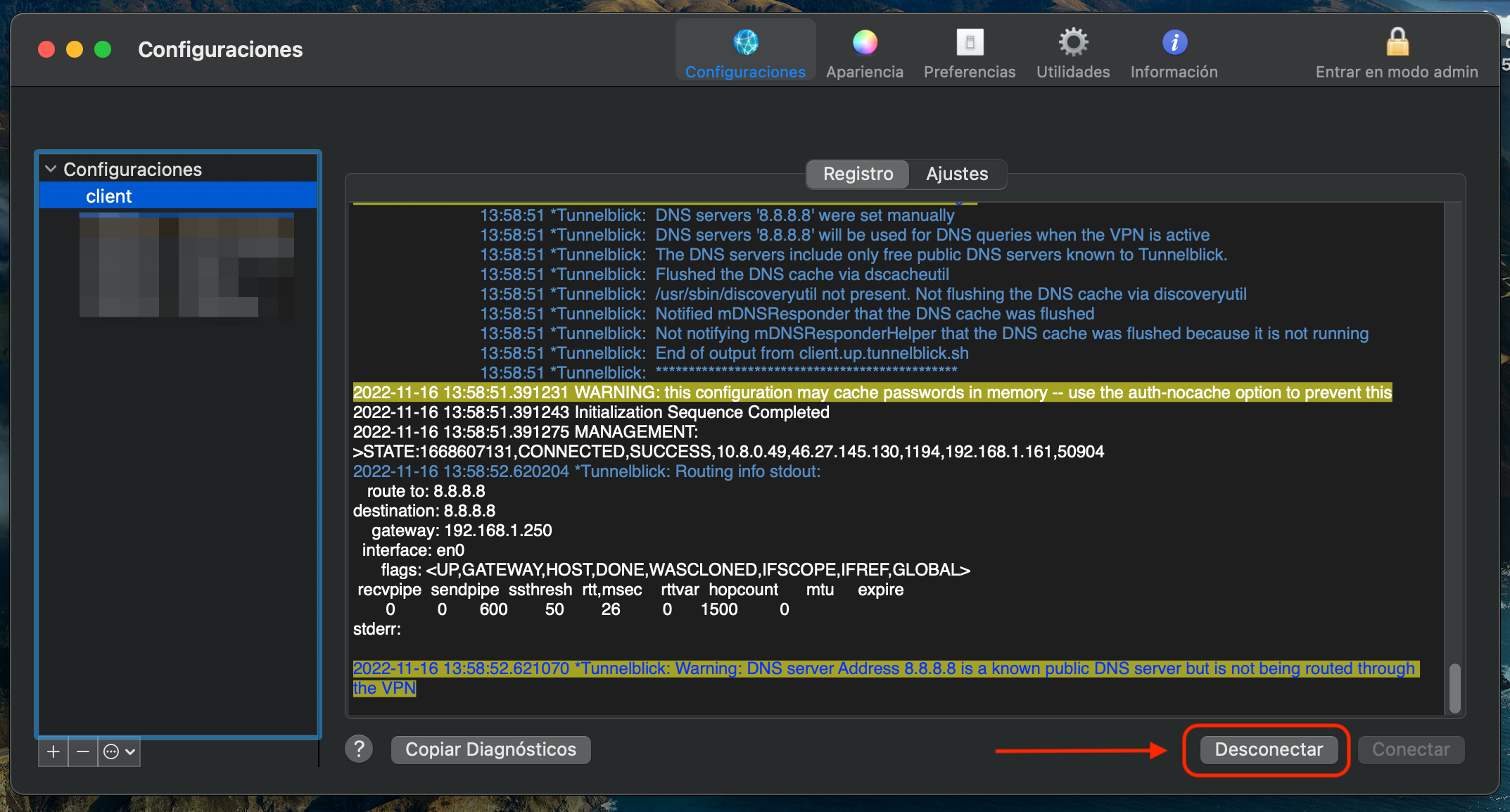
En caso de tener problemas con la conexión, tenemos disponible la pestaña "Registro" para ver los mensajes de la conexión y así poder depurar un posible problema.
Añadir los servidores DNS de TeideHPC a nuestra conexión#
Para facilitar la vida a los usuarios y no tengan que recordar todas las IPs de acceso al cluster de cómputo tenemos en funcionamiento un servidor DNS que permite resolver esas direcciones sin la necesidad de recordad la IP.
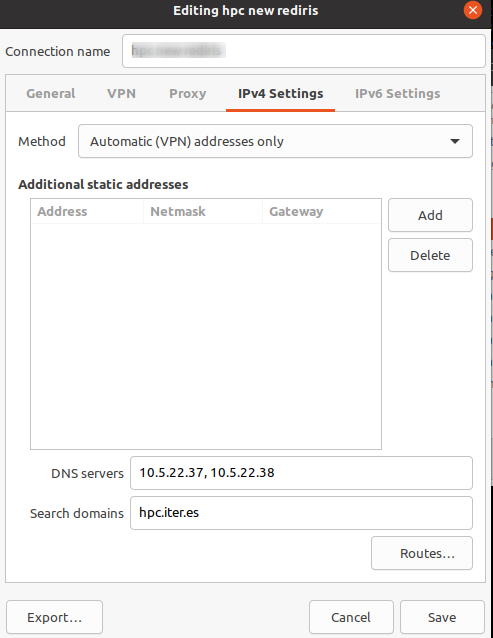
| Nombre | IP Address |
|---|---|
| dns1 | 10.5.22.37 |
| dns2 | 10.5.22.38 |
Para configurarla siga los siguientes pasos:
Añadir servidores DNS. Usuarios linux.#
Los usuarios linux pueden añadir los DNS de TeideHPC en la configuración de su conexión VPN
Mediante línea de commandos.#
Lista tus conexiones:
nmcli connection show
NAME UUID TYPE DEVICE
XXXXXXX 00000000-7777-4f70-a5ca-a5be5c9551b5 wifi --
....
teide hpc 12345678-1234-1234-1234-622e596d061e vpn --
....
Con el siguiente comando añade nuestros servidores DNS
nmcli c modify "<vpn-settings-name>" ipv4.dns '10.5.22.37 10.5.22.38'
Añade el dominio de búsqueda
nmcli c modify "<vpn-settings-name>" ipv4.dns-search 'hpc.iter.es'
Mediante interfaz gráfica (Ubuntu y Debian)#
En una terminal escribe el siguiente comando:
nm-connection-editor
Selecciona tu conexión VPN y edítala. En la pestaña IPv4 Settings podrás añadir los DNS y el dominio de búsqueda como se muestra a continuación.
Añadir servidores DNS. Usuarios Windows#
Antes de añadir tu tu fichero de configuración client.ovpn al cliente de OpenVPN añade las siguientes líneas:
Ended: OpenVPN
Ended: Seguridad y VPN
Primeros pasos ↵
¿Cómo iniciar sesión en TeideHPC?#
Con la llegada de la nueva infraestructura a TeideHPC, se han dispuesto varios nodos de login que permintan tener la redundancia y alta disponibilidad necesaria para mantener el cluster operativo el 100% del tiempo.
Para el acceso a la infraestructura el TeideHPC dispone de los siguientes 3 puntos de acceso, uno para cada cluster mediante consola y un acceso web.
| TeideHPC | AnagaGPU | Acceso web |
|---|---|---|
| hpclogin.hpc.iter.es | gpulogin.hpc.iter.es | https://ondemand.hpc.iter.es |
| 10.5.22.100 | 10.5.22.101 | https://myjobs.hpc.iter.es |
Recuerde que debe estar conectado a la VPN para acceder
Para asegurar que el número de usuarios no se concentre en un sólo nodo de login, el cual eventualmente acaba saturándose debido a preferencias de acceso y ejecuciones no intencionadas de los usuarios, se ha dispuesto un balanceador de carga para cada cluster el cual se encarga de distribuir a los usuarios de forma equitativa en cada uno de los 2 nodos de login que tiene cada cluster.
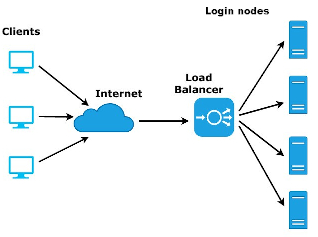
Todos los nodos de login comparten todo su $HOME
Es decir, independientemente a qué IP de acceso se conecten y de qué nodo le sea asignado, sus datos serán accesibles de manera indistinta.
Una vez accedes, es posible ir de un nodo a otro sin ningún tipo de restricción
El software disponible en cada cluster NO es el mismo
No todos los nodos son iguales, cada cluster tiene un tipo de nodos según la arquitectura de estos por lo que el software está compilado en su mayoría atendiendo a la arquitectura de los nodos.
En la página principal de esta documentación puede ver ver qué architecturas existen en TeideHPC.
Acceso web a TeideHPC.#
Para acceder via web a TeideHPC, puedes usar el siguiente enlace: https://ondemand.hpc.iter.es
Qué es OnDemand
Básicamente es un servicio web que permite lanzar sus ejecuciones de una forma más visual, sencilla y amigable para el usuario. Para más información visite la sección en esta misma web
Recuerda que necesitarás tus credenciales de usuario para iniciar sesión.
Si tienes algún problema con el acceso, no dudes en contactarnos.
Acceso para los usuarios de Linux y macOS#
A través de una terminal:
Usar DNS en lugar de IPs
Recuerda que puedes acceder a usando nuestro DNS siempre que los hayas añadido a tu configuración.
SSH Alias#
Para que sea más sencillo trabajar y no estar recordando la IP del servidor, podemos utilizar un alias para guardar la conexión. Para ello, editamos el fichero ~/.ssh/config y añadimos lo siguiente (si no exite, lo creamos):
Host teidelogin
Hostname 10.5.22.100
User miusuario
Host anagalogin
Hostname 10.5.22.101
User miusuario
Ahora para conectarnos por ssh a los nodos de login podemos hacerlo de la siguiente manera:
Acceder con clave pública SSH#
Podemos acceder a los nodos de login sin contraseña utilizando una clave pública SSH. Si no tenemos ninguna, podemos hacerlo de la siguiente manera:
Una vez se ejecute el comando, nos pedirá dos cosas:
- Una localización donde guardar la clave y un nombre para el archivo.
- Una contraseña para encriptar la clave y que tendremos que utilizar cada vez que usemos la clave pública.
Podemos dejar vacío ambos campos. En el caso de la localización, por defecto, el par de claves se guardarán en el directorio ~/.ssh:
- Para la clave privada:
~/.ssh/id_rsa - Para la clave pública:
~/.ssh/id_rsa.pub
Warning
La clave privada la debe guardar usted y no compartirla con nadie. Es la que se usará para realizar la autenticación con el servidor. Si la pierde, no podrá conectarse utiliziando la clave pública ssh.
En cuanto a la contraseña, eso ya es desición de cada uno.
Para copiar la clave pública SSH al nodo de login, debe hacer lo siguiente:
Nos pedirá la contraseña de nuestro usuario para proceder y ya podremos conectarnos a los nodos de login sin necesidad de contraseña, simpre y cuando lo hagamos desde el ordenador donde está la clave privada.
Acceso para usuarios de Windows#
Los usuarios de windows disponen de varias alternativas para conectarse vía SSH a los nodos de login. Entre ellas están PuTTY y MobaXterm:
Acceso remoto SSH con PuTTy#
PuTTy es un cliente de red que soporta los protocolos SSH, Telnet y Rlogin y sirve principalmente para iniciar una sesión remota con otra maquina o servidor. Es de licencia libre y a pesar de su sencillez es muy funcional y configurable.
Una vez descargado e instalado el software habrá que seguir los siguientes pasos para establecer la conexión con los nodos de login de TeideHPC
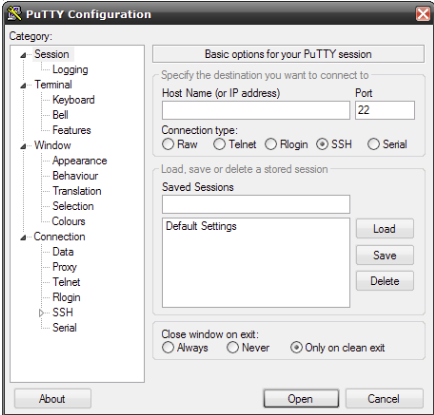
-
En el menú de configuración seleccione la categoría Session.
-
Introduzca el nombre de su dominio o IP en el campo Host Name y seleccione el protocolo SSH.
-
Introduzca un nombre para esta conexión en el campo Saved Sessions.
-
Vuelva al menú de configuración y seleccione la categoría SSH.
-
Asegúrese de que está marcada la opción 2 en Preferred SSH protocol version.
-
Seleccione nuevamente la categoría Session.
-
Para guardar la configuración pulse Save y Open para conectar.
Consejos:
-
For slow connections you can enable compression. You can find a checkbox in the Connection > SSH menu.
-
SSH version 2 must be set as the preferred protocol version in Connection > SSH menu.
MobaXterm#
MobaXterm es un toolbox para trabajar de manera remota. En una sola aplicación proporciona un montón de funciones (SSH, X11, RDP, VNC, FTP, sFTP, MOSH, comandos unix) que están diseñadas para programadores, webmasters, administradores de TI y prácticamente todos los usuarios que necesitan manejar sus trabajos remotos de una manera más simple.
La versión gratuita tiene ciertas limitaciones como el número de sesiones simultáneas, pero puede usarse libremente sin fines comerciales.
Para configurar un cliente SSH en MobaXterm, sigue estos pasos:
-
Iniciar MobaXterm: Abre MobaXterm en tu computadora.
-
Sesión Nueva: Haz clic en el botón "Session" en la parte superior izquierda de la pantalla de inicio de MobaXterm.
-
Seleccionar SSH: En la ventana de "Session settings", selecciona la opción "SSH" en la lista de tipos de sesión.
-
Configurar Parámetros de SSH:
- Remote host: Introduce la dirección IP o el nombre de host del servidor al que deseas conectarte.
- Specify username: Puedes especificar un nombre de usuario si no quieres ingresar el nombre de usuario cada vez que te conectes al servidor.
- Port: Cambia el puerto si es necesario (el puerto por defecto para SSH es 22).
- Advanced SSH settings: Si necesitas configuraciones avanzadas como el uso de una clave SSH específica, haz clic en "Advanced SSH settings" y realiza las configuraciones necesarias.
-
Guardar la sesión (opcional): Puedes guardar la configuración de la sesión para futuras conexiones. Dale un nombre a la sesión y guarda la configuración.
-
Conectar: Haz clic en "OK" o "Open" para iniciar la conexión SSH. Si es la primera vez que te conectas a este servidor, es posible que se te pida que verifiques la clave del host y que ingreses tu contraseña.
-
Autenticación: Ingresa tu contraseña cuando se te solicite. Si configuraste una clave SSH y la contraseña de la clave, ingrésala.
-
Sesión Iniciada: Una vez que se complete la autenticación, deberías estar conectado a tu servidor a través de SSH en la terminal de MobaXterm.
En este enlace puede encontrar una gúia más detallada:
Cuentas de usuario#
Las cuentas de usuarios son proporcionados por el equipo de administración de TeideHPC previa solicitud. Las cuentas de usuario tienen carácter personal e intransferible, lo que sinigfica que está prohibido compartir las credenciales VPN, así como las contraseñas con terceras personas.
Recordamos que solo se permite una conexión VPN simultánea, es decir, no podrá estar conectado a la VPN al mismo tiempo desde dos dispositivos.
Para cualquier consulta, dificultad o necesidad de asistencia adicional, no dudes en ponerte en contacto con nosotros a través del correo electrónico support@hpc.iter.es. Estamos aquí para ayudarte.
Almacenamiento#
Salvo casos particulares, las cuentas tendrán asociadas el siguiente esquema de almacenamiento:
| Almacenamiento | Capacidad | Descripción |
|---|---|---|
| /home | 5 GB | Recomendable no almacenar datos o código en esta partición. Cuando se alcance su máxima capacidad, tendrá que mover los archivos a /data |
| /data | X TB | Partición con una "cuota soft" sobre el almacenamiento contratado. Para grandes volumenes será necesario solicitarlo mediante el email de soporte (support@hpc.iter.es). Es accesible en /home/<usuario>/data |
| /scratch | -- | Almacenamiento sólo disponible bajo solicitud expresa |
| /local/<jobid> | 300GB | En el HDD local del nodo que le asigne el planificador a la ejecución. El contenido de esta partición se elimina una vez finalizada la ejecución. Al lanzar una ejecución al gestor de colas se crea la carpeta en el path indicado. El jobid es acccesible a través de la variable de entorno $SLURM_JOBID |
| /lustre | X TB | Almacenamiento de alto rendimiento basado en LUSTRE con mayores prestaciones en cuanto a ancho de banda. Debe utilizarse como almacenamiento de datos en utilización por tareas de cómputo, una vez disponibles los resultados tienen que transferirse a home o data, ya que la permanencia de datos en esta partición no está asegurada y puede someterse a operaciones de limpieza periódicamente. Es accesible /home/<usuario>/lustre |
Cualquier cambio en este esquema de almacenamiento será notificado.
Tu directorio home tiene un límite soft de 5GB.
¡¡¡Recomendamos guardar tus entornos virtuales, datos de aplicación y resultados en el directorio data or lustre (si necesitas almacenamiento de alto rendimiento!!!
Copias de seguridad#
Los datos de los usuarios están respaldados por el sistema de copias de seguridad del sistema de almacenamiento. El esquema de las copias de seguridad es el siguiente:
- Para /home, 6 copias horarias, 2 copias diarias y 2 semanales.
- Para /data, 6 copias horarias, 2 copias diarias y 2 semanales.
Para /local no hay copias de seguridad, porque es un almacenamiento situado en los discos duros de los nodos de cómputo, enfocado a mejorar el rendimiento de los trabajos. Una vez éstos terminen, el contenido de esta partición se borra por completo. La idea es que, una vez se inicie la ejecución del trabajo, el usuario copiar los datos con los que va a trabajar a esta partición del nodo y, antes de que finalize por completo el trabajo, es decir, en el mismo script de ejecución, mueva los resultados obtenidos a su espacio en data.
Para /lustre tampoco hay ningún sistema de copias de seguridad por la misma razón. Es un almacenamiento dedicado a optimizar las ejecuciones de los usuarios, pero esta vez, utilizando la red infiniband que interconecta todos los nodos y que cuenta con velocidades muy superiores al resto de redes. La idea es que el usuario copie los datos de las ejecucuciones aquí, y cuando estas terminen, mueva los resultados de vuelta a su espacio en data. En este caso, nosotros no borramos nada, pero si por algún motivo ocurre algún problema y los datos se ven afectados o el usuario borra datos por equivocación, no hay copias de seguridad para recuperar dichos datos.
Repositorio con ejemplos#
El conocimiento no tiene ningún poder si no puede ser compartido. (José A. Pallavicini)
Según las solicitudes de nuestros usuarios experimentamos con diferentes aplicaciones y librerías e intentamos documentar ejemplos simples para ellos.
Visita nuestro repositorio en github https://github.com/hpciter/user_codes
Ended: Primeros pasos
Ended: Guías de usuario
Conceptos HPC ↵
Slurm ↵
Qué es SLURM#
SLURM es un sistema de planificador de trabajos y administración de clústeres de código abierto y altamente escalable para clústeres grandes como es el TeideHPC.
Este planificador tiene tres funciones clave.
-
Asigna acceso exclusivo y/o no exclusivo a los recursos (nodos de cómputo) a los usuarios durante un período de tiempo para que puedan realizar el trabajo.
-
Proporciona un marco de trabajo para iniciar, ejecutar y monitorear los trabajos (normalmente un trabajos paralelos) en el conjunto de nodos asignados.
-
Arbitra la disputa por recursos administrando una cola de trabajo pendiente.
Actualmente en el cluster se dispone de la versión 19 de SLURM.
Los conceptos más importantes dentro de slurm son:
- Nodos de cómputo.
- Particiones.
- Trabajos.
- Tareas que representan un proceso dentro de un trabajo.
Nodos de login#
Desde los nodos de login es desde donde el usuario interactúa con Slurm y desde donde lanza y monitoriza sus trabajos. Desde aquí, el usuario accede a sus datos y a los resultados de las ejecuciones.
Info
Hay que recordar que los nodos de login son de uso compartido por todos los usuarios, por lo que está prohibida la ejecución de software en dichos nodos. Para ello se debe usar el planificador Slurm.
Particiones#
Las particiones se pueden considerar colas de trabajos, cada una de las cuales pueden tenier una variedad de restricciones como límite de tamaño del trabajo, límite de tiempo del trabajo, usuarios autorizados a usarlo, etc. Al lanzarse los trabajos en una partición concreta, éstos son ordenados por prioridad dentro de una partición hasta que los recursos (nodos, procesadores, memoria, etc.) dentro de esa partición están agotados pudiendo quedar a la espera.
Las particiones definidas en nuestro cluster son las siguientes y sus únicas rectricciones son el tiempo y los usuarios que puede usarla:
| Partición | Tiempo máximo | |
|---|---|---|
| express | 3 horas | todos los usuarios |
| batch | 24 horas | todos los usuarios |
| long | 72 horas | todos los usuarios |
| fatnodes | -- | previa solicitud a los administradores |
| gpu | -- | previa solicitud a los administradores |
Si no se especifica ninguna, la partición por defecto es las batch.
Si su trabajo va a durar más del tiempo máximo que establecido por la partición donde lo ha lanzado contacte con support@hpc.iter.es para pedir una ampliación de tiempo límite.
Comandos más comunes en SLURM#
Para familariazarse con el planificador a continuación se detallan los comandos más comunes de slurm. Para obtener mas información acerca del comando como opciones siempre puede ejecutar
sbatch <script file>: lanzar un script al gestor de colassqueue: verificar el estado de los trabajos en las colasscancel <job_id list>: cancelar un trabajoscontrol show job <job_id>: obtener información del estado de un trabajosinfo: ver estado de las colas del sistemasalloc <opciones>: iniciar sesión interactiva (obtener un nodo para ejecutar)srun <aplicacion>: enviar un trabajo a ejecutar o inicia los pasos del trabajo en tiempo realsacct: consultar el accounting de la propia cuentasstat: obtener información sobre los recursos utilizados por un trabajo en ejecución
Puede ver una guía resumen más detallada en nuestra seccion Comandos útiles en slurm o en la página oficial de slurm.
Gestión de trabajos ↵
Cómo Ejecutar Trabajos en Slurm#
Lanzar una Ejecución#
Existen tres métodos principales para lanzar trabajos en Slurm: sesiones interactivas, ejecución de trabajos en tiempo real, y envío de trabajos mediante scripts. Cada método requiere especificar los recursos necesarios.
Ejecución de Sesión Interactiva#
Usando el comando salloc, Slurm proporcionará al usuario un nodo de cálculo donde, de manera interactiva, el usuario puede trabajar y ejecutar cualquier software necesario. Esta es una opción muy útil para probar nuevo software o nuevos datos para trabajar, sin la necesidad de lanzar trabajos a la cola, con el riesgo de que fallen tan pronto como comiencen.
Solicitar un único núcleo:
Aviso
Los parámetros predeterminados asignados por slurm son:
Solicitar múltiples núcleos:
En este comando, estamos solicitando acceso exclusivo a un nodo entero, asumiendo que el nodo dispone de 16 núcleos. Este tipo de solicitud es particularmente útil para tareas que requieren una gran cantidad de memoria y recursos de CPU, permitiendo que la aplicación aproveche completamente los núcleos del nodo sin compartirlos con otros trabajos. Esta configuración maximiza el rendimiento para cargas de trabajo intensivas en cálculo o memoria.
Solicitar un nodo de una partición particular, con un nombre de trabajo y una duración determinada:
Información
Después de asegurar los recursos, podrías ver un mensaje como:
Y cuando el trabajo comienza:
Toma nota!
Una vez que tenemos un nodo vía `salloc`, podemos, desde otro terminal, acceder a ese nodo vía **SSH** para tener varias sesiones abiertas en el mismo nodo y trabajar en múltiples cosas al mismo tiempo.
Saliendo de la sesión:
Una vez que salimos del nodo desde el terminal donde hicimos salloc, Slurm liberará el nodo y el trabajo se marcará como completado. Obviamente, una vez que salimos, todas las sesiones adicionales que hayamos abierto vía SSH se cerrarán automáticamente.
Ejecutando un Trabajo en Tiempo Real#
Usa el comando srun para lanzar un trabajo directamente en la cola:
Este comando envía directamente un trabajo solicitando 16 núcleos, lo cual es útil para aplicaciones que necesitan procesamiento paralelo.
Más opciones disponibles:
| Nombre | Dirección IP |
|---|---|
| -p <partition> | partición en la que se ejecutarán los trabajos |
| -N <nodes> | número de nodos |
| -n=<num_tasks> | número de tarea |
| --tasks-per-node=<number> | tarea por nodo (considerar -N) |
| -J <job_name> | nombre del trabajo |
| -t <days-HH:MM:SS> | tiempo esperado |
| -d=<type:job_id[:job_id]> | tipo de dependencia del trabajo y id de dependencia (opcional) |
| -o </path/to/file.out> | archivo para stdout (flujo de salida estándar) |
| -e </path/to/file.out> | archivo para sterr (flujo de error estándar) |
| -D <directory> | directorio predeterminado para ejecución |
| --mail-user=<email> | email para notificaciones de slurm |
| --mail-type=<eventos> | lista de eventos para notificaciones |
Ejecutar en SLURM vía un script#
El comando sbatch envía un trabajo a la cola para ser ejecutado por uno o más nodos, dependiendo de los recursos que se hayan especificado.
La estructura más básica para un script es la siguiente:
#!/bin/bash
#SBATCH -J <job_name>
#SBATCH -p <partition>
#SBATCH -N <nodes>
#SBATCH --tasks=<number>
#SBATCH --cpus-per-task=<number>
#SBATCH --constraints=<node architecture> # sandy, ilk (icelake)... architecture
#SBATCH -t <days-HH:MM:SS>
#SBATCH -o <file.out>
#SBATCH -D .
#SBATCH --mail-user=<email_account>
#SBATCH --mail-type=BEGIN,END,FAIL,TIME_LIMIT_50,TIME_LIMIT_80,TIME_LIMIT_90
##########################################################
module purge
module load <modules>
srun <application>
Diferencia Entre los Parámetros de CPU#
--cpus-per-task: Especifica el número de CPUs (núcleos) que se asignarán a cada tarea. Se utiliza cuando una tarea requiere más de un CPU para funcionar, como en aplicaciones que pueden utilizar multihilo o paralelismo a nivel de hilo.
--ntasks: Define el número total de tareas que se ejecutarán en el trabajo. Cada tarea es una instancia separada del programa que estás ejecutando. Se usa principalmente para la paralelización a nivel de tareas, como en programas que utilizan MPI (Interfaz de Paso de Mensajes).
--ntasks-per-node: Determina cuántas tareas se ejecutarán en cada nodo. Esto es útil cuando se desea controlar cómo se distribuyen las tareas entre los nodos asignados. A menudo se usa en conjunto con ntasks para asegurar una distribución específica de tareas por nodo.
Ejemplo#
Objetivo#
Deseas ejecutar un total de 8 tareas de tu aplicación, donde cada tarea utilizará 4 núcleos. Quieres distribuir estas tareas en 2 nodos.
Script de Slurm#
Este script configura Slurm para ejecutar un programa que se beneficia de la paralelización tanto a nivel de tarea como a nivel de hilo:
#!/bin/bash
#SBATCH -J ejemplo_paralelismo
#SBATCH -p batch # Partición batch
#SBATCH -N 2 # Solicitando 2 nodos
#SBATCH --ntasks=8 # Total de 8 tareas a ejecutar
#SBATCH --ntasks-per-node=4 # Distribuir 4 tareas por nodo
#SBATCH --cpus-per-task=4 # Cada tarea utilizará 4 CPUs (núcleos)
#SBATCH --time=01:00:00 # Límite de tiempo de una hora
#SBATCH -o resultado_%j.out # Salida estándar
#SBATCH -e errores_%j.err # Errores estándar
module load mi_modulo # Cargar los módulos necesarios
srun mi_aplicacion # Ejecutar la aplicación
Explicación del Script#
--ntasks=8: Este parámetro establece que el trabajo consistirá en 8 tareas independientes. En el contexto de MPI, podrías pensar en esto como lanzar 8 procesos distintos.
--ntasks-per-node=4: Indica que cada nodo asignado al trabajo deberá ejecutar 4 de estas tareas. Dado que has solicitado 2 nodos y quieres ejecutar 8 tareas en total, cada nodo manejará 4 tareas.
--cpus-per-task=4: Especifica que cada tarea debe utilizar 4 núcleos. Esto es útil para tareas que pueden ejecutar hilos de manera concurrente, aprovechando la paralelización a nivel de hilo dentro de cada tarea.
Resultado Esperado#
Con esta configuración, el sistema de Slurm distribuirá el trabajo en los 2 nodos disponibles, colocando 4 tareas en cada uno, y cada tarea utilizará 4 núcleos de CPU en el nodo asignado. Esto puede resultar en un uso eficiente del hardware disponible, maximizando el rendimiento del programa que se beneficia tanto de la paralelización a nivel de tarea como de hilo.
Ejecutar un trabajo en la cola#
Normalmente, un trabajo es creado mediante un script de lanzamiento (shell script) donde las primeras líneas del archivo deben contener las directivas SBATCH así como la línea de comienzo #!/bin/bash que indica el interprete de shell a usar.
Mi primer trabajo con slurm#
En el siguiente ejemplo es un sencillo script que le ayude a familiarizarse con ellos.
Simplemente realiza la solicitud de recursos (particiones, nº de nodos, memoria, tiempo máximo de ejecución, directorios de trabajo, ficheros de salida,....),comienza con una ejecución de comandos linux básicos (steps) y espera 120 segundos antes de finalizar el trabajo.
#!/bin/bash
#SBATCH --job=mi_primer_test # Nombre del trabajo
#SBATCH --partition=batch # Partición (express/sbatch/long/fatnodes)
#SBATCH --nodes=1 # Nº de nodos
#SBATCH --mem=30000M # Memoria solicitada por nodo (30000M or 60000M)
#SBATCH --tasks-per-node=1 # Nº tareas por nodo
#SBATCH --constrains=sandy # sandy, ilk (icelake)... arquitecture
#SBATCH --time=02:00 # Límite de tiempo
#SBATCH --output=file_%j.log # Log de salida estandar
#SBATCH --error=file_%j.err # Log de salida errores
#SBATCH -D . # Directorio de trabajo
#SBATCH --mail-user=EMAIL # Donde será enviado el mail
#SBATCH --mail-type=END,FAIL # Eventos email
##########################################################
# UN COMENTARIO
echo "Comienza mi script"
pwd
hostname
date
sleep 120
echo "Finaliza mi script"
El mismo script se puede escribir con la opciónes corta:
#!/bin/bash
#SBATCH -J mi_primer_test # Nombre del trabajo
#SBATCH -p batch # Partición (express/sbatch/long/fatnodes)
#SBATCH -N 1 # Nº de nodos
#SBATCH --mem=30000M # Memoria solicitada por nodo (30000M or 60000M)
#SBATCH --tasks-per-node=1 # Nº tareas por nodo
#SBATCH --constrains=sandy # sandy, ilk (icelake)... arquitecture
#SBATCH -t 02:00 # Límite de tiempo
#SBATCH -o file%j.log # Log de salida
#SBATCH -e file_%j.err # Log de salida errores
#SBATCH -D . # Directorio de trabajo
#SBATCH --mail-user=EMAIL # Donde será enviado el mail
#SBATCH –mail-type=END,FAIL # Eventos email
##########################################################
# UN COMENTARIO
echo "Comienza mi script"
pwd
hostname
date
sleep 120
echo "Finaliza mi script"
Guarde el fichero creado anteriormente con un nombre apropiado en un directorio de trabajo creado para ello, por ejemplo mi_primer_test.sh o mi_primer_test.sbatch.
Info
Hay determinadas opciones que tienen valores ya establecidos por defecto, como es la partición, donde la partición por defecto es la batch.
Para ver todas las opciones disponibles sobre las directivas sbatch puede visitar la documentación oficial de slurm o ejecutando los siguientes comandos:
Como lanzar un job con sbatch#
Para lanzar el trabajo solo tiene que ejecutar el siguiente comando.
Mi segundo trabajo con slurm#
En este segundo ejemplo simplemente cargaremos una aplicación (module) para poder usarla. Concretamente un módulo de python y ejecutaremos un pequeño script de python.
Es recomendable crear un entorno virtual para ejecutar python (virtualenv, venv, pyenv, conda environment, pipenv). Por ejemplo para usar venv, en el directorio de trabajo ejecutar:
- Crear el script de lanzamiento:
#!/bin/bash
#SBATCH --job=mi_python_test # Nombre del trabajo
#SBATCH --nodes=1 # Nº de nodos
#SBATCH --constrains=sandy # sandy, ilk (icelake)... arquitecture
#SBATCH --time=02:00 # Límite de tiempo
#SBATCH --output=file_%j.log # Log de salida estandar
#SBATCH --error=file_%j.err # Log de salida errores
#SBATCH --chdir=. # Directorio de trabajo
#SBATCH --mail-user=email # Donde será enviado el mail
#SBATCH --mail-type=END,FAIL # Eventos email
##########################################################
# antes de cargar el módulo vemos si ha ejecutable de python3
echo "python3 antes:"; python3 --version
# Carga modulos
module purge
module load GCCcore/11.2.0 Python/3.8.6
echo "python3 despues"; python3 --version
which python3
echo "COMIENZA STEP1"
# Activo el entorno de python
source /path/workdir/venv/bin/activate
# Lanzamos el script de python
python3 hello_world.py
echo "FINALIZA MI SCRIPT"
Recuerde que su directorio de trabajo es ., que es el mismo directorio donde está script de ejecución y. Si hello_world.py está en otro directorio, debe especificar la ruta completa.
Otra opción es usar la variable de entorno de slurm* SLURM_SUBMIT_DIR. Para lanzar el trabajo:
Useful Slurm commands#
Slurm proporciona una variedad de herramientas que permiten al usuario administrar y comprender sus trabajos. Este tutorial presentará estas herramientas y proporcionará detalles sobre cómo usarlas.
Encontrar información en la cola de trabajo con squeue#
El comando squeue es una herramienta que usamos para obtener información sobre los trabajos que están en la cola. De manera predeterminada, el comando squeue imprimirá el ID del trabajo, la partición, el nombre del trabajo, el usuario del trabajo, el estado del trabajo, el tiempo que lleva en ejecución, la cantidad de nodos y la lista de nodos asignados:
squeue
JOBID PARTITION NAME USER ST TIME NODES NODELIST(REASON)
111111 batch my_job myuser R 1:21:59 1 node0101-1
Podemos generar información no abreviada con la marca --long. Esta bandera imprimirá la información predeterminada no abreviada con la adición de un campo de límite de tiempo:
El comando squeue también brinda a los usuarios un medio para calcular la hora de inicio estimada de un trabajo agregando el indicador --start a nuestro comando. Esto agregará la hora de inicio estimada de Slurm para cada trabajo en nuestra información de salida.
Nota
La hora de inicio proporcionada por este comando puede ser inexacta. Esto se debe a que la hora calculada se basa en los trabajos en cola o en ejecución en el sistema. Si un trabajo con una prioridad más alta se pone en cola después de ejecutar el comando, su trabajo puede ser demorado.
Al verificar el estado de un trabajo, es posible que desee llamar repetidamente al comando squeue para buscar actualizaciones. Podemos lograr esto agregando el indicador --iterate a nuestro comando squeue. Esto ejecutará squeue cada n segundos, lo que permite una actualización frecuente y continua de la información de la cola sin necesidad de llamar repetidamente a squeue:
Presione ctrl-c para detener el bucle del comando y regresar a la terminal.
Estado de los trabajos#
Una vez que se ha enviado un trabajo a una cola de trabajos, la ejecución seguirá estos estados:
PENDINGoPD: El trabajo ha entrado en la cola pero aún no están disponibles los recursos solicitados para que empieze a trabajar, es decir, que no haya nodos libres.RUNNINGoR: El trabajo se está ejecutando en la cola con los recursos que se han solicitado.COMPLETEDoCD: El trabajo se ha ejecutado correctamente, o al menos, lo que se ha especificado en el script de lanzamiento.COMPLETINGoCG: El trabajo está en proceso de terminar en un estado correcto.SUSPENDoS: la ejecución del trabajo se ha suspendido y los recursos utilizados se han liberado para otros trabajos.CANCELLEDoCA: el trabajo ha sido cancelado o por el usuario o por los administradores de sistemas.FAILEDoF: Ha fallado la ejecución del trabajo.NODE_FAILoNF: Ocurrió un error con el nodo y el trabajo no pudo lanzarse. Por defecto, Slurm relanza el trabajo de nuevo.
Razones de que un trabajo esté en PENDING#
Cuando un trabajo se encuntra en el estado de PENDING, se añade la razón de porqué está pendiente para ejecutar y ésta puede ser:
-
(Resources): el trabajo está esperando hasta que estén disponibles los recursos solicitados.
-
(Dependency): el trabajo es dependiente de otro y, por tanto, no entrará a ejecutar hasta que se cumpla la condición establecida para la dependencia.
-
(DependencyNeverSatisfied): El trabajo está esperando por una dependencia que no ha sido cumplida. El trabajo se quedara en este estado para siempre, por tanto, hay que cancelar el trabajo.
-
(AssocGrpCpuLimit): El trabajo no se puede ejecutar porque se ha consumido la cuota asignada de CPU.
-
(AssocGrpJobsLimit): El trabajo no se puede ejecutar porque se ha alcanzado el límite de trabajos simultáneos que tiene permitido ejecutar el usuario o la cuenta.
-
(ReqNodeNotAvail): El nodo especificado no está disponible. Puede ser que esté en uso, que esté resevado o puede que esté marcado como "fuera de servicio".
Info
Para obtener más información sobre squeue, visite la página de Slurm en squeue
Detener trabajos con scancel#
En ocasiones, es posible que deba detener un trabajo por completo mientras se está ejecutando. La mejor manera de lograr esto es con el comando scancel. Este comando permite cancelar los trabajos que está ejecutando en los recursos de Research Computing utilizando la ID del trabajo. El comando se ve así:
Para cancelar varios trabajos, puede usar una lista de ID de trabajos separados por comas:
Info
Para obtener más información, visite el manual de Slurm en scancel
Información de estado con sstat#
El comando sstat permite a los usuarios obtener fácilmente información sobre el estado de sus trabajos actualmente en ejecución. Esto incluye información sobre el uso de la CPU, información de la tarea, información del nodo, tamaño del conjunto residente (RSS) y memoria virtual (VM). Podemos invocar el comando sstat como tal:
Formatear la salida del sstat#
De forma predeterminada, sstat extraerá mucha más información de la que se necesitaría en la salida predeterminada de los comandos. Para remediar esto, podemos usar el indicador --format para elegir lo que queremos en nuestra salida. El indicador de formato toma una lista de variables separadas por comas que especifican los datos de salida:
Algunas de estas variables se enumeran en la siguiente tabla:
| Variable | Descripción |
|---|---|
| avecpu | Promedio de tiempo de CPU de todas las tareas en el trabajo. |
| averss | Tamaño medio del conjunto residente de todas las tareas. |
| avevmsize | Memoria virtual promedio de todas las tareas en un trabajo. |
| jobid | ID del trabajo. |
| maxrss | Número máximo de bytes leídos por todas las tareas del trabajo. |
| maxvsize | Número máximo de bytes escritos por todas las tareas en el trabajo. |
| ntasks | Número de tareas en un trabajo. |
Por ejemplo, imprima la identificación de trabajo promedio de un trabajo, el tiempo de CPU, el máximo de rss y la cantidad de tareas. Podemos hacer esto escribiendo el comando:
Info
Se puede encontrar una lista completa de variables que especifican datos manejados por sstat con el indicador --helpformat o visitando la página de slurm en sstat.
Analizar trabajos terminados con sacct#
El comando sacct permite a los usuarios obtener información sobre el estado de los trabajos terminados. Este comando es muy similar a sstat, pero se usa en trabajos que se ejecutaron previamente en el sistema en lugar de los trabajos que se están ejecutando actualmente. Podemos usar la identificación de un trabajo.
- Para todos los trabajos ejecutados:
- Para un único trabajo, identificado por su ID:
De forma predeterminada, sacct solo extraerá los trabajos que han ejecutado en el día en curso. Podemos usar el indicador --starttime para decirle al comando que mire más allá de su caché de trabajos a corto plazo.
Para ver una versión no abreviada de la salida de sacct, use el indicador --long:
Formatear la salida del sacct#
Al igual que sstat, es posible que la salida estándar no proporcione la información que queremos. Para remediar esto, podemos usar el indicador --format para elegir lo que queremos en nuestra salida. De manera similar, el indicador de formato es manejado por una lista de variables separadas por comas que especifican los datos de salida:
A continuación se proporciona una lista de algunas variables:
| Variable | Description |
|---|---|
| account | Cuenta con la que se ejecutó el trabajo |
| avecpu | Tiempo promedio de CPU de todas las tareas en el trabajo. |
| averss | Average resident set size of all tasks in the job. |
| cputime | Tiempo transcurrido de CPU usado por un job o paso |
| elapsed | Tiempo transcurrido de los trabajos con formato DD-HH:MM:SS |
| exitcode | El código de salida devuelto por el script de trabajo o salloc. |
| jobid | ID del trabajo. |
| jobname | Nombre del trabajo. |
| maxdiskread | Número máximo de bytes leidos por todas las tareas. |
| maxdiskwrite | Número máximo de bytes leidos por todas las tareas. |
| maxrss | El código de salida devuelto por el script de trabajo o salloc. |
| ncpus | Cantidad de CPU asignadas. |
| nnodes | Número de nodos usados. |
| ntasks | Número de tareas en un job. |
| priority | Prioridad Slurm. |
| qos | Calidad de servicio. |
| reqcpu | Número de CPUs solicitados |
| reqmem | Cantidad de memoria necesaria para un trabajo |
| user | Nombre de usuario de la persona que ejecutó el trabajo. |
Como ejemplo, suponga que desea buscar información sobre los trabajos que se ejecutaron el 12 de marzo de 2018. Desea mostrar información sobre el nombre del trabajo, la cantidad de nodos utilizados en el trabajo, la cantidad de CPU, el maxrss y el tiempo transcurrido. Su comando se vería así:
Como otro ejemplo, suponga que desea obtener información sobre los trabajos que se ejecutaron el 21 de febrero de 2018. Le gustaría obtener información sobre la identificación del trabajo, el nombre del trabajo, la calidad del servicio, la cantidad de nodos utilizados, la cantidad de CPU utilizadas, el RSS máximo y la CPU. tiempo, tiempo promedio de CPU y tiempo transcurrido. Su comando se vería así:
Info
Se puede encontrar una lista completa de variables que especifican datos manejados por sacct con el indicador --helpformat o visitando la página de slurm en sacct.
Control de trabajos en cola y en ejecución mediante scontrol#
El comando scontrol proporciona a los usuarios un mayor control de sus trabajos ejecutados a través de Slurm. Esto incluye acciones como suspender un trabajo, detener la ejecución de un trabajo o extraer información detallada sobre el estado de los trabajos.
Para suspender un trabajo que se está ejecutando actualmente en el sistema, podemos usar scontrol con el comando suspender. Esto detendrá un trabajo en ejecución en su paso actual que se puede reanudar en un momento posterior. Podemos suspender un trabajo escribiendo el comando:
Para reanudar un trabajo en pausa, usamos scontrol con el comando reanudar:
Slurm también proporciona una utilidad para retener trabajos que están en cola en el sistema. Retener un trabajo colocará el trabajo en la prioridad más baja, efectivamente "reteniendo" el trabajo para que no se ejecute. Un trabajo solo se puede retener si está esperando que el sistema se ejecute. Usamos el comando de espera para poner un trabajo en estado de espera:
Luego podemos liberar un trabajo retenido usando el comando de release:
scontrol también puede proporcionar información sobre trabajos mediante el comando show job. La información proporcionada por este comando es bastante extensa y detallada, así que asegúrese de borrar la ventana de su terminal, recopilar cierta información del comando o canalizar la salida a un archivo de texto separado:
Streaming de salida a un archivo de texto#
Canalizar la salida a Grep y encontrar líneas que contengan la palabra "Tiempo"#
Variables de entorno de salida en SLURM#
Dentro de los script de ejecución se pueden invocar ciertas variables con las que podemos conocer cierta información de la ejecución dentro un script.
Documentación para variables de entono de slurm
Las más usadas son las siguiente:
| Variable | |
|---|---|
| SLURM_ARRAY_JOB_ID | Job array's master job ID number. |
| SLURM_JOB_ID | The ID of the job allocation. |
| SLURM_JOBID | New version for the ID of the job allocation |
| SLURM_JOB_DEPENDENCY | Set to value of the --dependency option |
| SLURM_JOB_NAME | Name of the job. |
| SLURM_JOB_NODELIST | List of nodes allocated to the job |
| SLURM_JOB_NUM_NODES | Total number of nodes in the job's resource allocation |
| SLURM_JOB_PARTITION | Name of the partition in which the job is running |
| SLURM_NODELIST | List of nodes allocated to the job |
| SLURM_SUBMIT_DIR | The directory from which sbatch was invoked |
Script para ver las variables de slurm.#
Ejecutando el siguiente script usted puede ver las variables nombradas en el apartado anterior:
#!/bin/bash
#SBATCH -J GNUParallel -o %x-%J.out
#SBATCH --time=00:10:00
#SBATCH --mem-per-cpu=2G
#SBATCH -n 16
#SBATCH -c 4
# SBATCH --ntasks-per-node=8
#SBATCH --constrains=<node arquitecture> # sandy, ilk (icelake)... arquitecture
date
echo "SUBMITTED ON: $SLURM_SUBMIT_HOST IP: $SLURM_LAUNCH_NODE_IPADDR DIR: $SLURM_SUBMIT_DIR NODES ALLOCATED: $SLURM_JOB_NODELIST"
echo "RUNNING ON: $(hostname) $SLURMD_NODENAME"
echo "JOB_ID: $SLURM_JOB_ID ARRAY_JOB_ID: $SLURM_ARRAY_JOB_ID"
echo "STEP: $SLURM_STEP_ID NODEID: $SLURM_NODEID LOCALID: $SLURM_LOCALID PROCID: $SLURM_PROCID"
echo "ARRAY_TASK_COUNT: $SLURM_ARRAY_TASK_COUNT ARRAY_TASK_ID: $SLURM_ARRAY_TASK_ID ARRAY_TASK_MAX: $SLURM_ARRAY_TASK_MAX ARRAY_TASK_MIN: $SLURM_ARRAY_TASK_MIN ARRAY_STEPSIZE: $SLURM_ARRAY_TASK_STEP"
echo "Args: $*"
sleep 10
Investigar un trabajo fallido#
No siempre los trabajos se ejecutan correctamente. Hay una lista de motivos por los que los trabajos o las aplicaciones se detienen o fallan. Las causas más comunes son:
- Exceder los límites de recursos solicitados, como la memoria o el tiempo límite, por ejemplo.
- Errores específicos del software.
- Errores en el procesamiento de los datos.
Nota
Es importante recopilar mensajes de error/salida ya sea escribiendo dicha información en la ubicación predeterminada o especificando ubicaciones específicas mediante las opciones --error/--output, por ejemplo, aunque esto dependerá de cada software.
Los mensajes de error y de salida son el punto de partida para investigar un error en el trabajo.
Exceder los límites de recursos#
Cada partición define límites máximos y predeterminados para el tiempo de ejecución y el uso de la memoria. Dentro de la especificación del trabajo, los límites actuales se pueden definir dentro de los rangos. Para una mejor programación, se deben estimar los requisitos del trabajo y adaptar los límites a las necesidades. Cuanto más bajos sean los límites mejor, así SLURM podrá encontrar un lugar. Además, cuanto menos gastos generales de recursos se especifican, menos recursos se desperdician, como por ejemplo, con la memoria.
Info
Si un trabajo excede el tiempo de ejecución o el límite de memoria, SLURM matará el trabajo.
Información de error#
En ambos casos, el archivo de errores proporciona información adecuada:
- Tiempo límite:
(...)
slurmstepd: error: *** JOB 41239 ON fnode01 CANCELLED AT 2016-11-30T11:22:57 DUE TO TIME LIMIT ***
(...)
- Límite de memoria:
(...)
slurmstepd: error: Job 41176 exceeded memory limit (3940736 > 2068480), being killed
slurmstepd: error: Exceeded job memory limit
slurmstepd: error: *** JOB 41176 ON fnode01 CANCELLED AT 2016-11-30T10:21:37 ***
(...)
Errores de Software#
Slurm captura el código de salida de un trabajo y lo guarda como parte del registro del trabajo. Para trabajos lanzados con sbatch, se captura el código de salida del script. Para trabajos lanzados con srun, el código de salida será el valor de retorno del comando ejecutado. Cualquier código de salida distinto de cero se considera un error de trabajo y da como resultado un estado de trabajo de FAILED.
Si una señal es responsable de la terminación de un trabajo/paso, el número de la señal también se capturará y se mostrará después del código de salida (separado por dos puntos).
Según el orden de ejecución de los comandos en el script sbatch, es posible que un comando específico falle, pero el script por lotes devolverá cero, lo que indica que se realizó correctamente. Por ejemplo:
#!/bin/bash
#SBATCH --job=my_r_test # Nombre del trabajo
#SBATCH --nodes=1 # Nº de nodos
#SBATCH --constrains=sandy # sandy, ilk (icelake)... arquitecture
#SBATCH --time=02:00 # Límite de tiempo
#SBATCH --output=file_%j.log # Log de salida estandar
#SBATCH --error=file_%j.err # Log de salida errores
#SBATCH --chdir=. # Directorio de trabajo
#SBATCH --mail-user=email # Donde será enviado el mail
#SBATCH --mail-type=END,FAIL # Eventos email
##########################################################
Rscript fail.R
echo "Script finished"
El código de salida y el estado indican incorrectamente que el trabajo finalizó correctamente:
sbatch job_sbatch.sh
Submitted batch job 41585
sacct -j 41585
JobID JobName Partition Account AllocCPUS State ExitCode
------------ ---------- ---------- ---------- ---------- ---------- --------
41585 Simple E + all id 1 COMPLETED 0:0
41585.batch batch id 1 COMPLETED 0:0
Solo el archivo de salida específico de R muestra el error:
Puede evitar este problema "saliendo" con un código de salida adecuado tan pronto como falle el comando:
#!/bin/bash
#SBATCH --job=my_r_test # Nombre del trabajo
#SBATCH --nodes=1 # Nº de nodos
#SBATCH --constrains=sandy # sandy, ilk (icelake)... arquitecture
#SBATCH --time=02:00 # Límite de tiempo
#SBATCH --output=file_%j.log # Log de salida estandar
#SBATCH --error=file_%j.err # Log de salida errores
#SBATCH --chdir=. # Directorio de trabajo
#SBATCH --mail-user=email # Donde será enviado el mail
#SBATCH --mail-type=END,FAIL # Eventos email
##########################################################
Rscript fail.R || exit 91
echo "Script finished"
Ahora, el código de salida y el estado coinciden con el verdadero resultado:
sbatch job_sbatch.sh
Submitted batch job 41925
sacct -j 41925
JobID JobName Partition Account AllocCPUS State ExitCode
------------ ---------- ---------- ---------- ---------- ---------- --------
41925 Simple E + all id 1 FAILED 91:0
41925.batch batch id 1 FAILED 91:0
Compruebe siempre los archivos de salida específicos de la aplicación en busca de mensajes de error.
Límites de memoria Slurm#
Slurm impone un límite de memoria en cada trabajo. De forma predeterminada, es deliberadamente relativamente pequeño: 2 GB por nodo. Si su trabajo usa más que eso, recibirá un error que indica que su trabajo ha excedido la memoria solicitada (Exceeded job memory limit).
Para establecer un límite mayor, agregue a su envío de trabajo:
donde X es la cantidad máxima de memoria que usará su trabajo por nodo, en MB.
Cuanto mayor sea su conjunto de datos de trabajo, mayor deberá ser, pero cuanto menor sea el número, más fácil será para slurm encontrar un lugar para ejecutar su trabajo.
Para determinar un valor apropiado, consulte siguiente sección.
Cómo estudiar la eficiencia de un job#
Muchas veces nos preguntamos cómo puedo saber qué tan eficiente es mi trabajo y para ello tenemos el comando seff.
donde el JOBID es el id del trabajo en el que estás interesado. Por ejemplo:
$ seff 1553
Job ID: 1553
Cluster: teide
User/Group: viddata/viddata
State: COMPLETED (exit code 0)
Nodes: 4
Cores per node: 16
CPU Utilized: 2-11:55:56
CPU Efficiency: 89.73% of 2-18:47:28 core-walltime
Job Wall-clock time: 01:02:37
Memory Utilized: 26.08 GB (estimated maximum)
Memory Efficiency: 23.85% of 109.38 GB (27.34 GB/node)
Solicite memoria un poco mayor a lo que seff dice.
Debe configurar la memoria que solicita en algo un poco más grande que lo que dice seff.
seff informa del máximo de memoria usada en jobs paralelos.
Tenga en cuenta que para trabajos paralelos que abarcan varios nodos, esta es la memoria máxima utilizada en cualquier nodo; si no está configurando una distribución uniforme de tareas por nodo (por ejemplo, con --ntasks-per-node), el mismo trabajo podría tener valores muy diferentes cuando se ejecuta en diferentes momentos.
Espera a que el trabajo termine satisfactoriamente.
También tenga en cuenta que el número registrado por slurm para el uso de la memoria será inexacto si el trabajo finalizó de forma no satisfactoria. Para obtener una medición precisa, debe tener un trabajo que se complete correctamente, ya que slurm registrará el pico de memoria real.
Memoria máxima por tipo de nodo#
| Tipo de nodo | Solicitud máxima de memoria en slurm | |
|---|---|---|
| Sandy bridge 16 Cores - 32 GB | 30000 MB | |
| Sandy bridge 16 Cores - 64 GB | 62000 MB | |
| Fat Nodes 32 Cores - 256 GB | 254000 MB | bajo solicitud |
| Icelake Nodos GPU 64 Cores - 256 GB | 254000 MB | bajo solicitud |
¿Cómo puedo saber qué tan eficiente es mi trabajo?#
Puede ver la eficiencia de su trabajo comparando MaxRSS, MaxVMSize, Elapsed, CPUTime, NCPUS con el comando sacct.
sacct -j 999997 --format=User,JobID,Jobname%25,partition,elapsed,MaxRss,MaxVMSize,nnodes,ncpus,nodelist%20
User JobID JobName Partition Elapsed MaxRSS MaxVMSize NNodes NCPUS NodeList
--------- ------------ ----------------- ---------- ---------- ---------- ---------- -------- ---------- --------------------
eolicase 999996 WRF_2023080618 batch 13:32:47 4 64 node1511-[1-4]
999996.batch batch 13:32:47 216700K 815628K 1 16 node1511-1
999996.0 geogrid.exe 00:00:57 236240K 2762564K 4 8 node1511-[1-4]
999996.1 metgrid.exe 00:01:54 15395M 591912K 4 4 node1511-[1-4]
999996.2 real.exe 00:00:26 338148K 2928876K 4 16 node1511-[1-4]
999996.3 wrf.exe 13:26:36 598864K 3768748K 4 64 node1511-[1-4]
En este trabajo, ve que el usuario usó 64 núcleos y su trabajo se ejecutó durante 13,5 horas. Sin embargo, su tiempo de CPU es de 13,5 horas, que está cerca de las 64*13 horas. Si su código escala efectivamente según esta fórmula CPUTime = NCPUS * Elapsed su aplicación escala perfectamente. Si no lo es, el resultado divergirá de la fórmula y la mejor manera de probar esto y determinar cómo escala la aplicación es hacer algunas pruebas de escala.
Hay dos formas de hacer esto: Strong scaling (escalado fuerte) and Weak scaling (escalado débil).
Strong scaling (Escalado fuerte)#
El escalado fuerte es donde deja el tamaño del problema igual pero aumenta la cantidad de núcleos. Si su código se escala bien, debería tomar menos tiempo proporcional a la cantidad de núcleos que usa.
Weak scaling (escalado débil)#
La cantidad de trabajo por núcleo sigue siendo la misma, pero aumenta la cantidad de núcleos, por lo que el tamaño del trabajo se escala proporcionalmente a la cantidad de núcleos. Por lo tanto, si su código se escala en este caso, el tiempo de ejecución debería seguir siendo el mismo.
Por lo general, la mayoría de los códigos tienen un punto en el que la escala se rompe debido a ineficiencias en el código.
Por lo tanto, más allá de ese punto, no hay ningún beneficio en aumentar la cantidad de núcleos que arroja al problema. Ese es el punto que quieres buscar. Esto se ve más fácilmente trazando el registro de la cantidad de núcleos frente al registro del tiempo de ejecución.
Consejos de uso#
Tip: Reservar nodos de computo completos
En los nodos de cómputo se recomienda reservar nodos completos utilizando la opción -N <nodes\>, para que no interfieran ejecuciones de otros usuarios entre sí. Recuerde que la facturación de estos nodos es por uso de nodo.
Tip: Enviar un trabajo con sbatch
Es aconsejable el enviar el trabajo mediante sbatch así como los el uso de los modificadores -D <directorio\> y -t <tiempo\>.
Tip: Número de tareas por nodo
Es posible realizar ejecuciones sin utilizar todos los cores disponibles en el nodo. Para ello sólo hay que solicitar el número de nodos mediante -N X y el número de procesos a ejecutar en cada nodo con --tasks-per-node:
Tip: Notificaciones del gestor de trabajos slurm
Es posible gestionar la notificación automática de ciertos eventos del trabajo con las siguientes directivas.
#SBATCH --mail-user=EMAIL # Email de notificación de eventos
#SBATCH --mail-type=EVENT1,EVENT2,... # Eventos notificables
- Aclaración sobre los eventos por correo de Slurm:
Slurm puede enviar correos a la dirección especificada sobre una serie de eventos que le ocurran al trabajo. Dichos eventos pueden ser:
- BEGIN: cuando el trabajo entra en ejecución.
- END: cuando la ejecución del trabajo finalizada.
- FAIL: cuando la ejecución del trabajo falla.
- TIME_LIMIT: cuando el trabajo alcanza el tiempo máximo de ejecución.
- TIME_LIMIT_50: cuando el trabajo haya alcanzado el 50% del tiempo límite.
- TIME_LIMIT_80: cuando el trabajo haya alcanzado el 80% del tiempo límite.
- TIME_LIMIT_90: cuando el trabajo haya alcanzado el 90% del tiempo límite.
- ARRAY_TASKS: envía una notificación por email por cada trabajo del array. Si, al usar arrays, no se especifica esta opción, se enviará un email como si fuera un único trabajo.
- ALL: todos los tipos de eventos.
De todos los eventos posibles, recomendamos que se utilicen los relacionados con el consumo de tiempo límite permitido, TIME_LIMIT_50, TIME_LIMIT_80 y TIME_LIMIT_90. De esta forma, el usuario es consiente del tiempo que le queda al trabajo y, si fuese necesario, puede enviar a tiempo un correo a los administradores para que se le amplíe el tiempo de ejecución al trabajo.
Ended: Gestión de trabajos
Temas avanzados ↵
Ejecuciones secuenciales#
La unidad de reserva mínima para ejecutar en TeideHPC es el nodo, por lo que, independientemente del trabajo a ejecutar, a la hora de realizar el accounting del mismo, se considerará que se ha hecho uso de nodos completos. Es decir, el cómputo de horas de uso de la infraestructura viene dado por el número de horas que cada nodo está ejecutando el trabajo en cuestión, se use o no todos los recursos disponibles del mismo.
Para que el usuario no se vea perjudicado por este hecho, habrá de estructurar sus ejecuciones de manera que pueda agruparlas en igual cantidad de número de cores al de los nodos (16).
Las ejecuciones secuenciales suelen requerir muchas ejecuciones de trabajos a pocos cores, por lo que el usuario deberá estructurar los datos de entrada para las ejecuciones en carpetas o nombres de ficheros identificados mediante un número de trabajo, de manera que éste se pueda manipular de manera sencilla dentro del script de lanzamiento.
Una vez se tengan los datos de entradas organizados de esta manera se puede proceder a la ejecución de la misma, lanzando en un script de submit tantas tareas como quepan en un nodo.
Ejemplo de ejecución sequencial de trabajos de 1 core#
El siguiente script de ejemplo lanza 16 trabajos de 1 core simultáneamente.
# !/bin/bash
#SBATCH -J <job_name>
#SBATCH -p <partition>
#SBATCH -N 1
#SBATCH --constrains=<node arquitecture> # sandy, ilk (icelake)... arquitecture
#SBATCH -t <days-HH:MM:SS>
#SBATCH -o <file.out>
#SBATCH -D .
##########################################################
module purge
module load <modules>
for i in {1..16}; do
srun --ntasks=1 --exclusive --output=slurm-%J.out serial-program --input /path/to/input.$i &
done
# wait until all background processes are ended
wait
El comando srun lanzará los trabajos individuales en diferentes cores. El símbolo & al final de la línea significa que el trabajo se ejecute en segundo plano, de manera que no haya que esperar para lanzar la siguiente tarea. El comando wait del final evita que el trabajo termine hasta que no hayan terminado todos los procesos anteriores.
Ejemplo ejecución secuencial trabajos de 4 cores#
El siguiente script de ejemplo lanza 4 trabajos de 4 cores simultáneamente lo que hace un total de 16 cores utilizados:
# !/bin/bash
#SBATCH -J <job_name>
#SBATCH -p <partition>
#SBATCH -N 1
#SBATCH --constrains=<node arquitecture> # sandy, ilk (icelake)... arquitecture
#SBATCH -t <days-HH:MM:SS>
#SBATCH -o <file.out>
#SBATCH -D .
##########################################################
module purge
module load <modules>
srun --ntasks=4 --exclusive --output=slurm-%J.out serial-program --input /path/to/input_1 &
srun --ntasks=4 --exclusive --output=slurm-%J.out serial-program --input /path/to/input_2 &
srun --ntasks=4 --exclusive --output=slurm-%J.out serial-program --input /path/to/input_3 &
srun --ntasks=4 --exclusive --output=slurm-%J.out serial-program --input /path/to/input_4 &
# wait until all background processes are ended
wait
Ejecución de arrays#
La ejecución de arrays requerirá de una preparación previa por parte del usuario.
El usuario deberá estructurar los datos de entrada para las ejecuciones en carpetas o nombres de ficheros identificados mediante un número de trabajo, de manera que éste se pueda manipular de manera sencilla dentro del script de lanzamiento.
Una vez se tengan los datos de entrada organizados de esta manera, se puede proceder a la ejecución de los trabajos, lanzando en un script de submit tantas tareas como se necesiten.
Ejecución de un array de 10 trabajos a un nodo#
# !/bin/bash
#SBATCH -J <job_name>
#SBATCH -p <partition>
#SBATCH -N 1
#SBATCH -N <nodes>
#SBATCH --task=<number>
#SBATCH --cpus-per-task=<number>
#SBATCH --constrains=<node arquitecture> # sandy, ilk (icelake)... arquitecture
#SBATCH -t <days-HH:MM:SS>
#SBATCH --array=0-10
## %A JobId de la tarea principal (script de lanzamiento del arrayjob)
## %a Índice de la tarea dentro del arrayjob
## %j JobId de la tarea dentro del arrayjob en el gestor de colas
#SBATCH -o <array-%A-%a-%j.out>
#SBATCH -D .
#SBATCH --mail-type END
#SBATCH --mail-user <mail to notify>
##########################################################
module purge
module load <modules>
echo "Array job $SLURM_ARRAY_JOB_ID -> $SLURM_ARRAY_TASK_ID"
srun program
echo "End array job $SLURM_ARRAY_JOB_ID -> $SLURM_ARRAY_TASK_ID"
Ejecución de un array de 100 trabajos con sólo 10 trabajos simultáneos#
# !/bin/bash
#SBATCH -J <job_name>
#SBATCH -p <partition>
#SBATCH -N 1
#SBATCH -t <days-HH:MM:SS>
#SBATCH –array=0-100%10
## %A JobId de la tarea principal (script de lanzamiento del arrayjob)
## %a Índice de la tarea dentro del arrayjob
## %j JobId de la tarea dentro del arrayjob en el gestor de colas
#SBATCH -o <array-%A-%a-%j.out>
#SBATCH -D .
#SBATCH --mail-type END
#SBATCH --mail-user <mail to notify>
##########################################################
module purge
module load <modules>
echo "Array job $SLURM_ARRAY_JOB_ID -> $SLURM_ARRAY_TASK_ID"
srun program
echo "End array job $SLURM_ARRAY_JOB_ID -> $SLURM_ARRAY_TASK_ID"
Trabajos dependendientes#
Esta página describe la función de dependencia de trabajos en SLURM.
Es una función se utiliza cuando se encadenan varios trabajos dependientes unos de otros. Por ejemplo:
-
Un trabajo de preprocesamiento con 1 núcleo debe ser seguido por una simulación con 16 núcleos. Los resultados deben procesarse posteriormente con un solo trabajo principal.
-
Un trabajo de procesamiento posterior debe enviarse después de que finalicen todas las tareas de una matriz de trabajo.
Uso#
El trabajo dependiente debe lanzarse utilizando el comando de sbatch especificando la opción --dependency=<type>:<listOfJobIDs>. El tipo puede ser:
after: el trabajo se lanza después de que el primer trabajo entre a ejecutar, es decir, que esté RUNNING.afterok: el trabajo se lanza después de que el primer trabajo haya terminado con éxito.afterany: el trabajo se lanza después de que el primer trabajo haya terminado, independientemente de si ha fallado o no.afternotok: el trabajo se lanza después de que el primer trabajo haya terminado en fallo.aftercorr: una tarea de un array de trabajos puede empezar a ejecutarse después de que el ID de otro trabajo del array haya finalizado con éxito.singleton: el trabajo puede empezar a ejecutarse cuando cualquier otro trabajo con el mismo nombre y del mismo usuario haya terminado.
Ejemplo
El trabajo subyacente (del que depende este trabajo) debe enviarse primero. El ID de trabajo relacionado se puede capturar recopilando la salida del comando sbatch con la opción --parsable:
Cómo Trabajar con la partición /local#
Cada uno de los nodos de cómputo dispone de una partición de 300GB, llamada /local, que el usuario puede utilizar mientras está utilizando el nodo. Cuando un nodo es asignado a un usuario, en esta partición se crea una carpeta con el ID del trabajo y cuyo propietario es el usuario, de esta forma, en este directorio el usuario puede crear, modificar o borrar ficheros.
El uso de esta partición no está restringido a ninguna cola, se puede utilizar incluso cuando se utiliza el nodo en modo interactivo, a través del comando sbatch.
Note
Una vez termine por completo la ejecución, se eliminará el contenido de esta partición, por lo que se deben mover los datos resultantes de la ejecución a, por ejemplo, la partición /data, una partición destinada para que cada usuario pueda trabajar.
Ejemplo de ejecución utilizando la partición /local#
# !/bin/bash
#SBATCH -J <job_name>
#SBATCH -p <partition>
#SBATCH -N 1
#SBATCH --constrains=<node arquitecture> # sandy, ilk (icelake)... arquitecture
#SBATCH -o <out.log>
#SBATCH -e <error.log>
#SBATCH -D .
##########################################################
module purge
module load <modules>
# Copy the data to /local
cp file1 file2 file3 ... /local/$SLURM_JOBID/
# Move into the /local directory
cd /local/$SLURM_JOBID
# Run software
...
# Once everything is finished, we move the results to our working directory
mv result1 result2 result3 ... ~/data/work_dir/
Paralelismo#
Si está trabajando en problemas complejos y de gran escala que requieren informática de alto rendimiento (HPC), es posible que se pregunte cómo elegir la mejor arquitectura para sus necesidades.
Los sistemas HPC se pueden clasificar en dos tipos principales: memoria compartida (Shared memory) y sistemas de memoria distribuida (Distributed memory).
Paralelismo de memoria compartida (threading)#
En el Paralelismo de memoria compartida o shared-memory parallelism (SM), las aplicaciones logran el paralelismo al ejecutar más de un subproceso a la vez en los núcleos dentro de un nodo. Cada uno de los subprocesos ve y manipula la misma memoria que asignó el proceso inicial. Los subprocesos son ligeros y rápidos y procesan de forma independiente partes del trabajo. Con el paralelismo SM, los trabajos están limitados a la cantidad total de memoria y núcleos en un nodo.
Para ejecutar una aplicación con subprocesos correctamente a través de Slurm, deberá especificar una serie de restricciones de Slurm. Por ejemplo, para iniciar un trabajo de Slurm para su aplicación con subprocesos que utilizará 16 subprocesos, haga lo siguiente:
#!/bin/bash
#SBATCH -J my_job
# Numero de Nodos y cores por nodo
#SBATCH -N 1
#SBATCH --cpu-per-task=16
#SBATCH --mem=45000
#SBATCH --partition=batch
module load GCC/12.2.0
srun ./myapp
Si opta por no usar srun para iniciar su aplicación, debe agregar esto a su script de trabajo de Slurm: export OMP_NUM_THREADS=16 Este número debe coincidir con --cpus-per-task.
Paralelismo de memoria distribuida (MPI)#
En el paralelismo de memoria de distribuida o distributed-memory parallelism (DM), una aplicación logra el paralelismo al ejecutar varias instancias de sí misma en varios nodos para resolver el problema. A cada instancia se le asigna su propia porción de memoria virtual y se comunica con otras instancias a través de una interfaz de paso de mensajes como MPI.
Por ejemplo, para usar 4 nodos y 16 procesadores por nodo,
#!/bin/bash
#SBATCH -J my_job
#SBATCH -N 4
#SBATCH --tasks=16
#SBATCH --mem=28000
#SBATCH --partition=batch
module load intel/2021b intel-compilers/2021.4.0 impi/2021.4.0
srun ./myapp
Paralelismo híbrido: DM + SM#
En el paralelismo híbrido, las aplicaciones logran el paralelismo con el uso de subprocesos y tareas MPI. Este tipo de paralelización combina las características de los dos modelos anteriores, lo que permite que un programa ejecute subprocesos en varios nodos del clúster.
Los trabajos híbridos pueden ejecutarse potencialmente de manera más eficiente (consumiendo menos memoria y escalando más) al reducir la sobrecarga de comunicación MPI de un trabajo. Esto se puede hacer sustituyendo hilos livianos por rangos MPI.
Para configurar trabajos para usar DM+SM, primero asegúrese de que su aplicación lo admita.
#!/bin/bash
#SBATCH –cpus-per-task=12 #same as -c 12
#SBATCH –ntasks=4 #same as -n 4
#SBATCH –ntasks-per-node=2
module load gompi/2022b
srun ./myapp
Los trabajos de DM pueden afectar el rendimiento debido a los pasos de comunicación de MPI cuando se ejecuta la aplicación en demasiados nodos.
Por ejemplo, si tiene un trabajo de DM que funciona mejor con 64 cores, puede solicitar que su trabajo se ejecute soólo en 4 nodos con nodes=4. Por supuesto, al hacer esto, es probable que su trabajo tarde más en comenzar debido a la restricción adicional del trabajo, pero podría valer la pena para sus análisis. Lo siguiente mejor que puede hacer es pedirle a Slurm que use preferiblemente 4 nodos, pero si no es posible, use 5 o 6. Debe especificar esto con --nodes=4-6 Sin especificar --nodes, su trabajo de MPI podría ejecutarse en cualquier cantidad de nodos en el clúster.
OpenMP/Multithreading vs. MPI#
Si bien hay varias formas de solicitar una cierta cantidad de núcleos de CPU para su programa, observe la siguiente distinción:
- Solicitar ntask (nº) cores CPU para MPI (procesos distintos)
Estas tareas se pueden distribuir en varios nodos de cómputo.
- Solicitar nodes ntask-per-node (nº) cores CPU para MPI (procesos distintos) en el mismo nodo
Esto distribuye sobre X nodos de cómputo Y tareas.
- Solicitar cpu-per-task (nº) de CPU cores para aplicaciones multithread (eg. OpenMP)
--cpus-per-task" especifica cuántas CPU puede usar cada tarea. ¡Estos siempre se asignarán dentro de un sólo nodo de cómputo, nunca a varios nodos!
Algunos consejos#
Para una aplicación MPI simple, use
Para una aplicación simple de OpenMP/multiproceso, use
Para una aplicación híbrida, use:
La opción SBATCH --ntasks-per-core=# sólo es adecuada para nodos de cómputo que tengan HyperThreading habilitado en hardware/BIOS
En TeideHPC, el HyperThreading está desactivado por defecto, es decir #SBATCH --ntasks-per-core=1
Haz tus propios test de escalabiliddad
Comience con 2 nodos y estudie los resultados y aumente la cantidad de nodos o tareas poco a poco.
Ejemplo básico: usar srun or no usarlo#
Esto siempre generará una línea, porque el script sólo se ejecuta en uno de los nodos
srun hace que el script ejecute su comando en los nodos trabajadores y, como resultado, debería obtener 8 líneas de saludo.
Ejemplo básico:Usar ntask y una aplicación de 1 thread.#
- Usando el valor por defecto de ntasks=1
El número de tareas predeterminado se especificó en 1 y, por lo tanto, la segunda tarea no puede comenzar hasta que la primera tarea haya finalizado. Este trabajo tardará en alrededor de 22 segundos. Desglosando esto:
sacct -j1425 --format=JobID,Start,End,Elapsed,NCPUS
JobID Start End Elapsed NCPUS
------------ ------------------- ------------------- ---------- ----------
1425 2023-07-13T20:51:44 2023-07-13T20:52:06 00:00:22 1
1425.batch 2023-07-13T20:51:44 2023-07-13T20:52:06 00:00:22 1
1425.0 2023-07-13T20:51:44 2023-07-13T20:51:56 00:00:12 1
1425.1 2023-07-13T20:51:56 2023-07-13T20:52:06 00:00:10 1
Aquí la tarea 0 comenzó y finalizó (en 12 segundos) seguida de la tarea 1 (en 10 segundos). Para hacer un tiempo de usuario total de 22 segundos.
- Usando ntasks=2
Ejecutando el mismo comando sacct como se especificó anteriormente:
sacct -j 515064 --format=JobID,Start,End,Elapsed,NCPUS
JobID Start End Elapsed NCPUS
------------ ------------------- ------------------- ---------- ----------
515064 2023-07-13T21:34:08 2023-07-13T21:34:20 00:00:12 2
515064.batch 2023-07-13T21:34:08 2023-07-13T21:34:20 00:00:12 2
515064.0 2023-07-13T21:34:08 2023-07-13T21:34:20 00:00:12 1
515064.1 2023-07-13T21:34:08 2023-07-13T21:34:18 00:00:10 1
Más ejemplos#
Visite nuestro repositorio en github https://github.com/hpciter/user_codes.git
GPUs en TeideHPC#
GPU es el acrónimo de Graphics Processing Unit y representa precisamente el corazón de una tarjeta gráfica al igual que la CPU lo hace en un PC. Aparte del corazón, también es su cerebro, ya que es la encargada de realizar todos los cálculos complejos que permiten que algunos programas pueden ejecutare mucho más rápido que en una CPU.
Entre las principales usos de las GPUs están los siguientes:
- Edición de vídeo
- Renderización de gráficos 3D
- Aprendizaje automático
- Aplicaciones científicas
- etc...
El clúster TeideHPC ofrece 2 modelos diferentes de GPU para usar con sus trabajos. Recomendamos echar un vistazo a la descripción del clúster para tener una idea de cómo se ve.
Modelos de GPU disponibles#
Estas son las GPU disponibles actualmente en TeideHPC:
| modelos | # nodos | # GPU/nodo | tipo slurm | Cores CPU/nodo | Memoria CPU/nodo | Capacidad de cómputo (*) | Memoria GPU (GiB) |
|---|---|---|---|---|---|---|---|
| Nvidia A100 | 16 | 4 | a100 | 64 | 256GB | 80 | 40 GB |
| Nvidia A100 | 1 | 8 | a100 | 64 | 512GB | 80 | 40 GB |
| Nvidia Tesla T4 | 4 | 1 | t4 | 32 | 256GB | 75 | 16 GB |
(*) Capacidad de cómputo o Compute Capability es un término técnico creado por NVIDIA como una forma compacta de describir qué funciones de hardware están disponibles en algunos modelos de GPU y no en otros. No es una medida de rendimiento y solo es relevante si está compilando sus propios programas de GPU. Consulte la página sobre programación CUDA para obtener más información.
Computación GPU en TeideHPC#
El clúster TeideHPC tiene una serie de nodos que tienen conectadas unidades de procesamiento de gráficos de propósito general (GPGPU) de NVIDIA. Es posible usar herramientas CUDA para ejecutar trabajo computacional en ellas y, en algunos casos de uso, ver aceleraciones muy significativas.
Como explicamos en la sección cómo ejecutar trabajos podemos utilizar 3 formas diferentes de enviar un trabajo a la cola de trabajos: utilizando una sesión interactiva, iniciando la aplicación en tiempo real o medio de un script de ejecución.
Cómo solicitar recursos de GPU#
- Para solicitar nodos de GPU o GPU primero debe comprender cómo está configurado su clúster así como las particiones, por este motivo, le recomendamos que consulte la página inicial donde tenemos una descripción del clúster que le puede ayudar.
- Básicamente hay 2 arquitecturas: icelake (nodos de GPU) y sandy (nodos de CPU).
- En base a estas arquitecturas se sólicitan los recursos dentro del cluster.
La forma de solicitar un nodo de GPU es utilizando la partición dedicada de gpu. Para poder utilizar esta partición hay que solicitar acceso. Además de especificar la partición, hay que utilizar las gres de SLURM
Recursos genéricos GRES (Generic Resource)#
En Slurm, GRES significa Recurso Genérico. GRES es una función que le permite especificar y administrar varios tipos de recursos genéricos, como GPU.
La funcionalidad GRES de Slurm permite la asignación, la programación y el seguimiento eficientes de estos recursos para los trabajos enviados. Ayuda a garantizar que los recursos solicitados estén disponibles y sean utilizados correctamente por los trabajos que los requieren.
Para usar GRES de manera efectiva, debe comprender cómo está configurado su clúster, cómo se definen los tipos y cantidades de GRES disponibles y especificar los requisitos de GRES al enviar trabajos.
Para obtener los tipos de GRES definidos en el clúster, puede usar:
Para conocer la lista de GRES en TeideHPC mira la columna GRES después de ejecutar este comando.
$ sinfo -o "%40N %10c %10m %35f %30G"
NODELIST CPUS MEMORY AVAIL_FEATURES GRES
node18109-1 64 257214 ilk,gpu,a100 gpu:a100:8
node2204-[3-4] 20 31906 ivy (null)
node17109-1,node17110-1,node18110-1,node 64 257214 ilk,viz,t4 gpu:t4:1
node0303-2,node0304-[1-4],node1301-[1-4] 16 30000+ sandy (null)
node17101-1,node17102-1,node17103-1,node17104-1, 64 257214 ilk,gpu,a100 gpu:a100:4(S:0-1)
Alternativamente, también se puede ver enumerando y filtrando el listado de nodos:
$ scontrol show nodes | egrep "NodeName|gres"
....
NodeName=node1315-4 Arch=x86_64 CoresPerSocket=8
NodeName=node2204-3 Arch=x86_64 CoresPerSocket=10
...
NodeName=node17101-1 Arch=x86_64 CoresPerSocket=32
CfgTRES=cpu=64,mem=257214M,billing=64,gres/gpu=4,gres/gpu:a100=4
NodeName=node17102-1 Arch=x86_64 CoresPerSocket=32
CfgTRES=cpu=64,mem=257214M,billing=64,gres/gpu=4,gres/gpu:a100=4
NodeName=node17103-1 Arch=x86_64 CoresPerSocket=32
CfgTRES=cpu=64,mem=257214M,billing=64,gres/gpu=4,gres/gpu:a100=4
NodeName=node17104-1 Arch=x86_64 CoresPerSocket=32
CfgTRES=cpu=64,mem=257214M,billing=64,gres/gpu=4,gres/gpu:a100=4
...
Como se puede observar, actualmente cada nodo de GPU dispone de 4 tarjetas A100 de Nvidia.
Ejemplos de uso de GRES#
- Para un nodo de GPU (icelake) con una GPU (Nvidia A100).
Tip
Recuerde que para utilizar GPUs tiene que utilizar la partición gpu, para la cual tiene que haber solicitado acceso.
Para solicitar una sola GPU en slurm simplemente agregue la directiva #SBATCH --gres=gpu:<model> a su script de envío de trabajo y le dará acceso a una GPU. Para solicitar varias GPU, agregue #SBATCH --gres=gpu:<modelo>:n, donde ‘n’ es la cantidad de GPU.
Entonces, si desea 1 CPU y 2 GPU de nuestros nodos GPU de uso general en la partición 'gpu', debe especificar:
Si prefiere usar una sesión interactiva, puede usar:
Mientras está en el nodo GPU, puede ejecutar nvidia-smi para obtener información sobre las GPU asignadas.
Scripts de ejemplo para un trabajo de GPU#
- Ejemplo usando una GPU Nvidia A100 compleata
#!/bin/bash
#SBATCH --partition=gpu
#SBATCH --nodes=1
#SBATCH --ntasks=1
#SBATCH --cpus-per-task=4
#SBATCH --gres=gpu:a100:1
#SBATCH --mem=8G
#SBATCH --time=1:00:00
module purge
module load CUDA/12.0.0
nvidia-smi
sleep 20
Más ejemplos#
Visita nuestro github https://github.com/hpciter/user_codes
Ejemplos de script#
En esta sección, le proporcionamos un conjunto de ejemplos que le serán útiles para configurar scripts según sus necesidades de investigación. Si está interesado en echarles un vistazo, están todos disponibles en el directorio /share/user_codes/.
Además, estos ejemplos están en nuestro repositorio. https://github.com/hpciter/user_codes.git
Para ejecutar los scripts, cópielos en su carpeta data.
$ tree /share/user_codes/
├── arrays
│ ├── 01-2node-4cpupertask
│ │ ├── 01-2nodes-4cpupertask.sbatch
│ │ └── README.md
│ ├── 02-1node-4cpupertask
│ │ ├── 02-1node-4cpupertask.sbatch
│ │ └── README.md
│ └── 03-1node-6cpupertask-ilk
│ ├── 03-1node-6cpupertask.sbatch
│ └── README.md
├── basics
│ ├── 00-sandy-nodes.sbatch
│ ├── 01-icelake-nodes.sbatch
│ └── README.md
├── gpu_basics
│ ├── 01_gpu_basic_a100.sbatch
│ ├── 02_gpu_basic_mig_partition.sbatch
│ └── README.md
├── images
│ └── teidehpc_logo.png
├── LICENSE
└── README.md
Trabajos de uno y varios núcleos#
Dependiendo del consumo de recursos, la simulación podría necesitar más de un procesador. En el script bash, es posible especificar cuántos núcleos se solicitan para ejecutar el trabajo.
Si la simulación usa más de un núcleo, debe agregar el parámetro --cpu-per-task o -c con la cantidad de núcleos de CPU utilizados por tarea.
Sin esta opción, el controlador asignará un núcleo. Recuerde especificar el número de tareas con el parámetro --ntasks o -n.
| Single core | Multi-core |
| #SBATCH --ntasks=X donde X => 1 | #SBATCH --ntasks=X donde X => 1 #SBATCH --cpus-per-task=Y donde Y > 1 |
OMP, MPI y Trabajos Híbridos#
Es posible encontrar diferentes tipos de paralelismo: OpenMP, OpenMPI o una solución híbrida combinando ambos. Por un lado, utilizará OpenMP para el paralelismo dentro de un nodo multinúcleo.
Dado que es una implementación de subprocesos múltiples, se debe definir una variable OMP_NUM_THREADS. En cambio, si el paralelismo es entre nodos, usarás OpenMPI. Entonces, en nuestro script de muestra, será necesario especificar la cantidad de nodos, la cantidad de tareas en cada nodo y cada CPU.
| OpenMP | OpenMPI | Hybrid |
|---|---|---|
| #SBATCH --cpus-per-tasks=X donde X > 1 export OMP_NUM_THREADS=X donde X > 1 |
#SBATCH --ntasks=X donde X => 1 #SBATCH --cpus-per-task=Y donde Y>1 #SBATCH --nodes=Z donde Z =>2 #SBATCH --ntasks-per-node=W donde W>1 #SBATCH --ntasks-per-socket=U donde U>1 module load OpenMPI/2.0.2-GCC-6.3.0-2.27 |
Combine both options |
Arrays de Jobs#
Con el uso de arrays puede ejecutar múltiples trabajos con los mismos parámetros. En su script debe especificar la opción --array.
| Array |
|---|
| #SBATCH --array=1-X donde X > 1 |
Trabajos de GPU#
Es imprescindible utilizar el parámetro --gres para reservar un recurso GPU y cargar el módulo CUDA.
| Nvidia A100 | Nvida Tesla T4 |
|---|---|
| #SBATCH --gres=gpu:a100:1 module load CUDA/8.0.61 |
#SBATCH --gres=gpu:t4:1 module load CUDA/8.0.61 |
Ended: Temas avanzados
Ended: Slurm
Transferencia de datos ↵
Transferencia de datos masiva#
Para realizar transferencias de datos se dispone de nodos de transferencia con un mayor ancho de banda y que disponen de IP pública, con lo que no es necesario utilizar la VPN. Estos nodos permiten copiar y descargar grandes cantidades de datos al espacio de usuario.
Actualmente tenemos dos nodos habilitados para tal efecto que proporcionan un mayor ancho de banda entre los propios nodos y el sistema de almacenamiento compartido. Estos nodos tienen las siguientes IPs públicas:
- 193.146.150.185
- 193.146.150.186
La trasferencia de información a través de estos nodos solo se permite mediante el uso del protocolo seguro SFTP(SecureSHell File Transfer Protocol o Secure File Transfer Protocol). SFTP nos permitirá descargar y subir archivos muy fácilmente, a la vez que nos proporciona confidencialidad y autenticación de los datos transmitidos, a diferencia de un servidor FTP donde no tenemos ningún tipo de seguridad, ya que las credenciales de usuario se envían sin cifrar, y todo el tráfico de datos también. Para ello es necesario disponer de un cliente de dicho protocolo en la máquina local, como pueden ser sftp en linux o psftp en windows.
Info
En estos nodos solo está permitido el uso de SFTP, no de SCP o Rsync. Estos últimos solo se pueden utilizar en los nodos de login, pero para copiar y descargar datos de gran tamaño recomendamos encarecidamente utilizar estos nodos por el mayo ancho de banda que tienen. Además, en los nodos de login, el SFTP está deshabilitado.
SFTP para usuarios Linux#
Se puede abrir la conexión al servidor a través de su IP pública:
Comandos más usados#
Una vez abierta la sesión, el comando help mostrará la lista de comandos que se pueden utilizar. A continuación se describen los más utilizados y son válidos para usuarios Linux como Windows:
sftp> help -- Muestra la ayuda.
sftp> cd dir -- Cambia el directorio de trabajo remoto.
sftp> lcd dir -- Cambia el directorio de trabajo local.
sftp> pwd -- Muestra el directorio de trabajo actual.
sftp> lpwd -- Muestra el directorio de trabajo actual local.
sftp> put file1.zip ... -- Sube un fichero desde el directorio de trabajo local al directorio de trabajo remoto
sftp> get file1.zip ... -- Descarga un fichero desde el directorio de trabajo remoto al directorio de trabajo local
sftp> put -r directory -- Sube un directorio desde el directorio de trabajo local al directorio de trabajo remoto
sftp> get -r directory -- Descarga un directorio desde el directorio de trabajo remoto al directorio de trabajo local
SFTP para usuarios Windows#
Para los usuarios windows existen multitud de aplicaciones tanto de linea de comandos como con interfaz gráfica. Entre ellas las más conocidas son: psftp, Filezilla y WinSPC.
psftp#
PSFTP es el cliente de línea de commandos SFTP que se instala con la aplicación PuTTY, uno de los clientes SSH más populares para windows.
Hay tres formas de abrir PSFTP
- Haciendo Click en inicio de Windows, buscar la aplicación Putty y luego PSFTP.
- Ir al directorio “C:\Program Files (x86)\PuTTY” y hacer doble click en psftp.exe.
- Iniciar la aplicación de línea de commandos de windows cmd o PowerShell.
Para esta última opción, es recomendable incluir el directorio en el que se ha instalado PSFTP dentro del PATH del usuario aquí
Se puede abrir la conexión al servidor a través de su IP pública.
Filezilla#
FileZilla es uno de los programas más utilizados para usarlo como cliente FTP/FTPS y FTPES, pero también incorpora la posibilidad de conectarnos a un servidor SFTP. Tan solo tendremos que introducir en la barra de direcciones la siguiente sintaxis Servidor: sftp://IP, y seguidamente, el usuario y la contraseña que se le ha suministrado, e introducir el puerto de escucha que tengamos configurado en el servidor SSH al que pretendemos conectarnos.
WinSCP#
WinSPC es un popular cliente para descargas gratuito que está disponible para Windows, soporta los protocolos SFTP, SCP, WebDAV y FTP, está enfocado principalmente para la transferencia de archivos, el uso de scripts y funcionalidades básicas de un administrador de archivos.
Otros#
SFTP para usuario de MAC#
Lo usuario de MAC pueden usar la terminal de la misma manera que los usuarios Linux o bien instalar una aplicación con interfaz gráfica como la siguiente:
Enlaces de interés#
Ended: Transferencia de datos
Ended: Conceptos HPC
Software y herramientas ↵
Entorno de módulos (Environment Modules)#
TeideHPC es un cluster compartido por cientos de usuarios, por lo que no es lo mismo la forma de proporcionar múltiples aplicaciones, en sus múltiples versiones, a multitud de usuarios, en un entorno de computación distribuida, que en un ordenador personal o en tu propio servidor.
Environment Modules es un sistema de gestión de software que permite a los usuarios de sistemas Unix-like, como Linux y macOS, y particularmente en entornos de computación de alto rendimiento (HPC), dinámicamente modificar su entorno, acceder a diferentes compiladores, bibliotecas y software que pueden tener múltiples versiones y dependencias.
Existen diferente implementaciones de Environment Modules pero la usada actualmente en TeideHPC es Lmod.
Lmod#
Lmod es un acrónimo de Lua Module System es una implementación específica del concepto de Environment Modules para la gestión de entornos de software en sistemas de alto rendimiento (HPC).
Lmod permite a los usuarios:
- cargar y descargar módulos de software dinámicamente.
- cambia las variables de entorno como PATH y LD_LIBRARY_PATH.
- facilitar el uso de diferentes versiones de aplicaciones y bibliotecas sin interferencias entre ellas.
Puedes obtener más información sobre Lmod en https://lmod.readthedocs.io/en/latest/.
¿Cómo se organiza el software en TeideHPC?#
En TeideHPC existen 2 clusters, TeideHPC y AnagaGPU
- Cada cluster tiene sus propios nodos de login y no disponen del mismo software instalado.
- El conjunto de módulos disponibles depende del Cluster que vaya a usar.
- Básicamente hay 2 arquitecturas: icelake (nodos con GPUs) y sandybrige(nodos de CPU).
- Mira la descripción del cluster en la página principal así cómo la página "Cómo solicitar recursos de GPU y cómputo".
El software instalado depende de la arquitectura de los nodos
Cada cluster tiene su propio software
Para ver el software disponible en cada cluster debe ingresar y verlo insitu.
Existen módulos que no dependen de la arquitectura
Nomenclatura plana.#
El esquema de módulos utiliza una nomenclatura específica para sus módulos, que normalmente sigue el formato:
- Nombre_del_software: Es el nombre del software o la biblioteca que se está instalando.
- Versión: Es la versión específica del software.
- Toolchain: Es la cadena de herramientas de compilación que incluye el compilador, la biblioteca MPI (si aplica), y otras bibliotecas de optimización de rendimiento que se usan para compilar el software. Por ejemplo, foss es una cadena de herramientas común que incluye GCC, OpenMPI, y otras.
- Variantes: Son modificadores adicionales que indican variantes específicas de la instalación, como optimizaciones específicas de hardware o la inclusión de ciertas características.
Por ejemplo, un módulo para la versión 6.0 de Unzip compilada con la cadena de herramientas GCCcore 12.2.0 podría tener una nomenclatura de módulo como
UnZip/6.0-GCCcore-12.2.0
Un ejemplo de módulo con distintas variantes y toolchain es el siguiente:
module spider 'Python'
-----------------------------------------------------------------------------------------------------------------
Python:
-----------------------------------------------------------------------------------------------------------------
Description:
Python is a programming language that lets you work more quickly and integrate your systems more
effectively.
Versions:
Python/2.7.18-GCCcore-11.2.0-bare
Python/2.7.18-GCCcore-11.2.0
Python/2.7.18-GCCcore-12.2.0-bare
Python/3.8.6-GCCcore-11.2.0
Python/3.8.6-intel-2021b
Python/3.9.6-GCCcore-11.2.0-bare
Python/3.9.6-GCCcore-11.2.0
Python/3.9.6-intel-2021b
Python/3.10.8-GCCcore-12.2.0-bare
Python/3.10.8-GCCcore-12.2.0
¿Qué es un Toolchain?#
El término "toolchain" se refiere al conjunto de herramientas de software que se utilizan para compilar y enlazar programas.
Un toolchain típicamente incluye compiladores para diferentes lenguajes de programación, bibliotecas de software matemáticas, y herramientas de enlazado y depuración.
Los toolchains están definidos por un conjunto de componentes que incluyen:
- Compiladores: GCC (GNU Compiler Collection), Intel Compiler, etc.
- Bibliotecas de comunicaciones MPI: Por ejemplo, OpenMPI, MPICH, Intel MPI, etc.
- Bibliotecas de matemáticas: BLAS (Basic Linear Algebra Subprograms) y LAPACK (Linear Algebra Package).
- Otras bibliotecas y herramientas: Como GMP (GNU Multiple Precision Arithmetic Library), FFTW (Fastest Fourier Transform in the West), etc.
El siguiente diagrama puede ver cómo se divide el software en función del Toolchain elegido. Básicamente se identifican 2 ramas en función del compilador principal: GNU GCC o Intel GCC
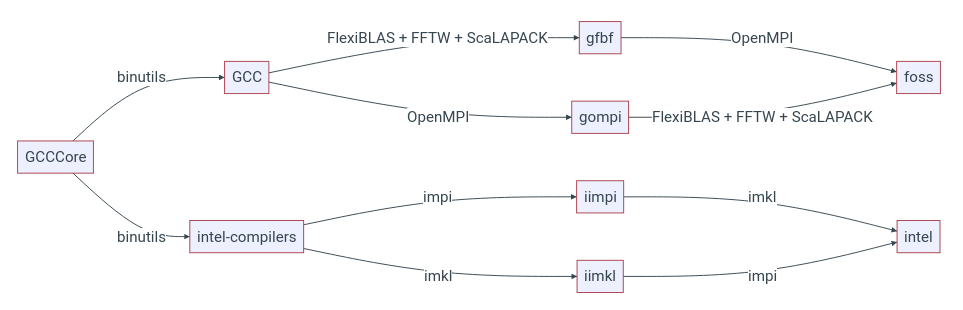
Asimismo, existen diferentes generaciones de estos toolchains que son incompatibles entre sí.
Toolchain foss#
El toolchain foss consta enteramente de software de código abierto (de ahí el nombre, derivado del término común 'FOSS', que es la abreviatura de "Free and Open Source Software").
En TeideHPC podemos identificar las siguientes generaciones para foss
| foss | binutils | GCC | Open MPI | FlexiBLAS | OpenBLAS | LAPACK | ScaLAPACK | FFTW |
|---|---|---|---|---|---|---|---|---|
| 2021b | 2.37 | 11.2.0 | 4.1.1 | 3.0.4 | 0.3.18 | (incl. with OpenBLAS) | 2.1.0 | 3.3.10 |
| 2022a | 2.38 | 11.3.0 | 4.1.4 | 3.2.0 | 0.3.20 | (incl. with OpenBLAS) | 2.2.0 | 3.3.10 |
| 2022b | 2.39 | 12.2.0 | 4.1.4 | 3.2.1 | 0.3.21 | (incl. with OpenBLAS) | 2.2.0 | 3.3.10 |
Toolchain intel#
El Toolchain Intel consta de compiladores y bibliotecas de Intel.
En TeideHPC podemos identificar las siguientes generaciones para intel
| intel | binutils | GCC | Intel compilers | Intel MPI | Intel MKL |
|---|---|---|---|---|---|
| 2021b | 2.37 | 11.2.0 | 2021.4.0 | 2021.4.0 | 2021.4.0 |
| 2022a | 2.38 | 11.3.0 | 2022.1.0 | 2021.6.0 | 2022.1.0 |
| 2022b | 2.39 | 12.2.0 | 2022.2.1 | 2021.7.1 | 2022.2.1 |
En la siguiente sección puede ver cómo usar modules para ver y cargar el software disponible en TeideHPC.
module spider foss
----------------------------------------------------
foss:
----------------------------------------------------
Description:
GNU Compiler Collection (GCC) based compiler toolchain, including OpenMPI for MPI support, OpenBLAS (BLAS
and LAPACK support), FFTW and ScaLAPACK.
Versions:
foss/2021b
foss/2022b
----------------------------------------------------
To find other possible module matches execute:
$ module -r spider '.*GCC.*'
-----------------------------------------------------
intel:
-----------------------------------------------------
Description:
Compiler toolchain including Intel compilers, Intel MPI and Intel Math Kernel Library (MKL).
Versions:
intel/2021b
intel/2022b
Other possible modules matches:
intel-compilers
-----------------------------------------------------
To find other possible module matches execute:
$ module -r spider '.*intel.*'
Software disponible en los clusters TeideHPC y AnagaGPU#
Antes de pasar a leer la siguiente sección, le recomendamos echar un vistazo a la sección "Herramienta de módulos"
El sistema de Environment Modules utiliza un conjunto de comandos que incluyen:
module overview: Muestra una lista general resumida de lo módulos módulos disponibles.module avail: Muestra todos los módulos disponibles en el sistema para cargar.module avail [módulo]: Muestra los módulos disponibles con ese nombre.module spider [módulo]: Realiza una búsqueda del un módulo concreto.module load [módulo]: Carga un módulo específico, lo que establece las variables de entorno necesarias para utilizar el software que el módulo representa.module unload [módulo]:Descarga un módulo, eliminando las variables de entorno asociadas con el software de la sesión del usuario.module swap [módulo_actual] [módulo_nuevo]: Intercambia un módulo cargado por otro, lo que es útil para cambiar rápidamente de versiones de software.module purge: Elimina todos los módulos cargados, limpiando el entorno del usuario de cualquier configuración realizada por módulos.module help [módulo]: Proporciona información de ayuda para un módulo específico, lo que puede incluir información sobre cómo usar el software, sus variables de entorno, etc.module whatis [módulo]: Muestra una breve descripción de lo que hace un módulo.module show [módulo]: Muestra información sobre lo que hace el módulo al entorno del usuario; es decir, qué variables de entorno ajusta y cómo.
En TeideHPC existen 2 clusters, TeideHPC y AnagaGPU
Por este motivo, el conjunto de módulos disponibles depende del Cluster que vaya a usar.
Cada cluster tiene sus propios nodos de login y no disponen del mismo software instalado.
La ejecución de software está prohibida en los nodos de login
En los nodos de login TeideHPC y AnagaGPU está prohibido ejecutar cualquier aplicación salvo comandos comunes de linux.
ml es una abreviatura de modules
Para evitar errores comunes al escribir el comandos modules tales como modles,moduls, mdules, etc es posible usar la abreviatura ml.
ml spider ... ml load ... ml purge ...
Significado de algunos módulos significativos.#
-
GCCcore: conjunto básico de compiladores de la GNU Compiler Collection: C, C++, Objective-C, Fortran.
-
GCC: colección de compiladores de GCCcore y librerías (GDB, binutils, glibc)
-
foss: el módulo foss consiste en su totalidad en el término común FOOS, que es la abreviatura de Free and Open source software.
-
gompi: toolchain que agrupa herramientas compiladas con GCC y OpenMPI
-
gompic: toolchain que agrupa herramientas compiladas con GCC+CUDA y OpenMPI
-
intel-compilers: Compiladores de Intel C, C++ & Fortran clasicos y oneAPI.
-
iimpi: Compilador Intel C/C++ y Fortran con soporte MPI de intel.
Ejemplo de uso de modules#
----------------/share/easybuild/software/common/modules/all -------------------------
EasyBuild (2) Go (1) Mamba (1) Miniconda3 (2) Singularity (1) Squashfs (1) slurm (1)
----------------/share/easybuild/software/x86_64/modules/all -------------------------
ADMIXTURE (1) Imath (1) UCX (2) jupyter-server (1)
ATK (1) Infernal (1) UDUNITS (2) libGLU (2)
ATLAS (1) JasPer (4) USEARCH (1) libarchive (3)
AdmixTools (2) Java (5) UnZip (2) libcerf (1)
Armadillo (2) JsonCpp (1) WPS (2) libdeflate (1)
Arrow (2) JupyterLab (2) WRF (2) libdrm (2)
Autoconf (4) LAME (1) X11 (2) libepoxy (1)
Automake (4) LAMPLD (2) XALT (1) libevent (1)
Autotools (5) LAPACK (1) XML-LibXML (2) libfabric (2)
BCFtools (1) LERC (1) XZ (2) libffi (2)
BEDTools (1) LLVM (2) Xerces-C++ (1) libgd (1)
------------------ /share/easybuild/software/common/modules/all -----------------
EasyBuild/4.7.0 Go/1.18.3 Miniconda3/22.11.1-1 Singularity/3.11.0 slurm/teide
EasyBuild/4.8.2 (D) Mamba/4.14.0-0 Miniconda3/23.5.2-0 (D) Squashfs/4.3
----------------- /share/easybuild/software/x86_64/modules/all --------------------
ADMIXTURE/1.3.0 UCC/1.1.0-GCCcore-12.2.0
ATK/2.38.0-GCCcore-12.2.0 UCX/1.11.2-GCCcore-11.2.0
ATLAS/0.9.9-foss-2022b UCX/1.13.1-GCCcore-12.2.0 (D)
AdmixTools/7.0.2-foss-2021b UDUNITS/2.2.28-GCCcore-11.2.0
AdmixTools/7.0.2-foss-2022b (D) UDUNITS/2.2.28-GCCcore-12.2.0 (D)
Armadillo/10.5.3-foss-2022b USEARCH/11.0.667-i86linux32
Armadillo/11.4.3-foss-2022b (D) UnZip/6.0-GCCcore-11.2.0
Arrow/6.0.0-foss-2021b UnZip/6.0-GCCcore-12.2.0 (D)
Arrow/11.0.0-gfbf-2022b (D) WPS/3.9.1-intel-2021b-dmpar
Autoconf/2.69-GCCcore-11.2.0 WPS/4.1-intel-2021b-dmpar (D)
Autoconf/2.71-GCCcore-11.2.0 WRF/3.9.1.1-intel-2021b-dmpar
Autoconf/2.71-GCCcore-12.2.0 WRF/4.4.1-foss-2022b-dmpar (D)
Autoconf/2.71 (D) X11/20210802-GCCcore-11.2.0
Automake/1.16.2-GCCcore-11.2.0 X11/20221110-GCCcore-12.2.0 (D)
Automake/1.16.4-GCCcore-11.2.0 XALT/3.0.1
...
-----------------------------------------------------
WRF:
-----------------------------------------------------
Description:
The Weather Research and Forecasting (WRF) Model is a next-generation mesoscale numerical weather
prediction system designed to serve both operational forecasting and atmospheric research needs.
Versions:
WRF/3.9.1.1-intel-2021b-dmpar
WRF/4.4.1-foss-2022b-dmpar
-----------------------------------------------------
For detailed information about a specific "WRF" package (including how to load the modules) use the module's full n
ame.
Note that names that have a trailing (E) are extensions provided by other modules.
For example:
$ module spider WRF/4.4.1-foss-2022b-dmpar
Currently Loaded Modules:
1) GCCcore/11.2.0 11) intel/2021b
2) zlib/1.2.11-GCCcore-11.2.0 12) libtirpc/1.3.1-GCCcore-11.2.0
3) binutils/2.37-GCCcore-11.2.0 13) JasPer/2.0.24-GCCcore-11.2.0
4) intel-compilers/2021.4.0 14) Szip/2.1.1-GCCcore-11.2.0
5) numactl/2.0.14-GCCcore-11.2.0 15) HDF5/1.10.7-iimpi-2021b
6) UCX/1.11.2-GCCcore-11.2.0 16) OpenSSL/1.1
7) impi/2021.4.0-intel-compilers-2021.4.0 17) cURL/7.78.0-GCCcore-11.2.0
8) imkl/2021.4.0 18) netCDF/4.7.4-iimpi-2021b
9) iimpi/2021b 19) netCDF-Fortran/4.5.3-iimpi-2021b
10) imkl-FFTW/2021.4.0-iimpi-2021b 20) WRF/3.9.1.1-intel-2021b-dmpar
- foss
El módulo foss consiste en su totalidad en el término común FOOS, que es la abreviatura de Free and Open source software. 2021a, 2021b, 2022b, etc indica la generación.
Este módulo consta de los siguientes paquetes y se encarga de precargarlos.
- binutils
- Compilador GNU GCC (C), g++ (C++) and gfortran (Fortran)
- Librería Open MPI
- Librería FlexiBLAS con OpenBLAS + LAPACK como backend
- Librería ScaLAPACK
- Librería FFTW (Fourier transform (DFT))
Currently Loaded Modules:
1) GCCcore/11.2.0 8) libpciaccess/0.16-GCCcore-11.2.0 15) OpenMPI/4.1.1-GCC-11.2.0
2) zlib/1.2.11-GCCcore-11.2.0 9) hwloc/2.5.0-GCCcore-11.2.0 16) OpenBLAS/0.3.18-GCC-11.2.0
3) binutils/2.37-GCCcore-11.2.0 10) OpenSSL/1.1 17) FlexiBLAS/3.0.4-GCC-11.2.0
4) GCC/11.2.0 11) libevent/2.1.12-GCCcore-11.2.0 18) gompi/2021b
5) numactl/2.0.14-GCCcore-11.2.0 12) UCX/1.11.2-GCCcore-11.2.0 19) FFTW/3.3.10-gompi-2021b
6) XZ/5.2.5-GCCcore-11.2.0 13) libfabric/1.13.2-GCCcore-11.2.0 20) ScaLAPACK/2.1.0-gompi-2021b-fb
7) libxml2/2.9.10-GCCcore-11.2.0 14) PMIx/4.1.0-GCCcore-11.2.0 21) foss/2021b
- gompi:
El módulo gompi precarga todo el software compilado con GNU GCC y OpenMPI. 2021a, 2021b, 2022b, etc indica la generación.
Currently Loaded Modules:
1) GCCcore/11.2.0 7) libxml2/2.9.10-GCCcore-11.2.0 13) libfabric/1.13.2-GCCcore-11.2.0
2) zlib/1.2.11-GCCcore-11.2.0 8) libpciaccess/0.16-GCCcore-11.2.0 14) PMIx/4.1.0-GCCcore-11.2.0
3) binutils/2.37-GCCcore-11.2.0 9) hwloc/2.5.0-GCCcore-11.2.0 15) OpenMPI/4.1.1-GCC-11.2.0
4) GCC/11.2.0 10) OpenSSL/1.1 16) gompi/2021b
5) numactl/2.0.14-GCCcore-11.2.0 11) libevent/2.1.12-GCCcore-11.2.0
6) XZ/5.2.5-GCCcore-11.2.0 12) UCX/1.11.2-GCCcore-11.2.0
- intel:
Este módulo común precarga los compiladores y librerías de Intel. 2021a, 2021b, 2022b, etc indica la generación.
- Compiladores Intel C/C++/Fortran (icc, icpc and ifort)
- binutils
- GCC, el cual sirve como base de los compiladores de intel.
- Librería Intel MPI
- Librería Intel Math Kernel Library (MKL) para funcionalidades de BLAS/LAPACK/FFT
Currently Loaded Modules:
1) GCCcore/12.2.0 5) numactl/2.0.16-GCCcore-12.2.0 9) iimpi/2022b
2) zlib/1.2.12-GCCcore-12.2.0 6) UCX/1.13.1-GCCcore-12.2.0 10) imkl-FFTW/2022.2.1-iimpi-2022b
3) binutils/2.39-GCCcore-12.2.0 7) impi/2021.7.1-intel-compilers-2022.2.1 11) intel/2022b
4) intel-compilers/2022.2.1 8) imkl/2022.2.1
Solicitud de instalación de nuevo software#
Para cualquier duda o problema, así como casos en los que se requiera instalación de software específico, mayor capacidad de cómputo, mayor espacio de almacenamiento, mayor duración de trabajos en los nodos de cómputo, utilización de máquinas no accesibles al usuario, etc. puede ponerse en contacto con los administradores de TeideHPC correo electronico support@hpc.iter.es indicando, si es necesario, la siguiente información de la aplicación:
- Nombre de la aplicación
- Versión
- Enlace de descarga o repositorio donde resida
- Otra información necesaria si lo desea
Guías de uso ↵
Conda#
Conda es un gestor paquetes y entornos de software libre utilizado sobre todo para paquetes de Python y R del ámbito científico, aunque también soporte otros lenguajes como C, C++, FORTRAN, Java, Scale, Ruby y Lua.
Utilizar Conda en TeideHPC#
Una vez nos hayamos conectados a los nodos de login, tendremos que cargar el módulo de miniconda para empezar a utilizar conda:
Una vez cargado el software, podemos, por ejemplo, ver la información de la versión de conda:
conda info
active environment : None
user config file : /home/vjuidias/.condarc
populated config files : /home/vjuidias/.condarc
conda version : 4.7.10
conda-build version : not installed
python version : 2.7.16.final.0
virtual packages :
base environment : /opt/envhpc/slurm19/rhel7/Miniconda2/4.7.10 (read only)
channel URLs : https://conda.anaconda.org/conda-forge/linux-64
https://conda.anaconda.org/conda-forge/noarch
https://conda.anaconda.org/bioconda/linux-64
https://conda.anaconda.org/bioconda/noarch
https://repo.anaconda.com/pkgs/main/linux-64
https://repo.anaconda.com/pkgs/main/noarch
https://repo.anaconda.com/pkgs/r/linux-64
https://repo.anaconda.com/pkgs/r/noarch
https://conda.anaconda.org/r/linux-64
https://conda.anaconda.org/r/noarch
package cache : /opt/envhpc/slurm19/rhel7/Miniconda2/4.7.10/pkgs
/home/vjuidias/.conda/pkgs
envs directories : /home/vjuidias/.conda/envs
/opt/envhpc/slurm19/rhel7/Miniconda2/4.7.10/envs
platform : linux-64
user-agent : conda/4.7.10 requests/2.22.0 CPython/2.7.16 Linux/3.10.0-327.el7.x86_64 centos/7.2.1511 glibc/2.17
UID:GID : 1136:1136
netrc file : None
offline mode : False
Ahora tenemos que inicializar la shell para utilizar Conda. Este paso es solo es necesario la primera vez. Si no lo hacemos, al utilizar conda, nos saldrá este mensaje:
CommandNotFoundError: Your shell has not been properly configured to use 'conda activate'.
To initialize your shell, run
$ conda init <SHELL_NAME>
Currently supported shells are:
- bash
- fish
- tcsh
- xonsh
- zsh
- powershell
See 'conda init --help' for more information and options.
IMPORTANT: You may need to close and restart your shell after running 'conda init'.
Por tanto, lo que tenemos que hacer es:
conda init bash
no change /opt/envhpc/slurm19/rhel7/Miniconda2/4.7.10/condabin/conda
no change /opt/envhpc/slurm19/rhel7/Miniconda2/4.7.10/bin/conda
no change /opt/envhpc/slurm19/rhel7/Miniconda2/4.7.10/bin/conda-env
no change /opt/envhpc/slurm19/rhel7/Miniconda2/4.7.10/bin/activate
no change /opt/envhpc/slurm19/rhel7/Miniconda2/4.7.10/bin/deactivate
no change /opt/envhpc/slurm19/rhel7/Miniconda2/4.7.10/etc/profile.d/conda.sh
no change /opt/envhpc/slurm19/rhel7/Miniconda2/4.7.10/etc/fish/conf.d/conda.fish
no change /opt/envhpc/slurm19/rhel7/Miniconda2/4.7.10/shell/condabin/Conda.psm1
no change /opt/envhpc/slurm19/rhel7/Miniconda2/4.7.10/shell/condabin/conda-hook.ps1
no change /opt/envhpc/slurm19/rhel7/Miniconda2/4.7.10/lib/python2.7/site-packages/xontrib/conda.xsh
no change /opt/envhpc/slurm19/rhel7/Miniconda2/4.7.10/etc/profile.d/conda.csh
modified /home/vjuidias/.bashrc
==> For changes to take effect, close and re-open your current shell. <==
Al hacer esto se nos ha modificado la shell, en este caso, la bash. Se nos han añadido las siguientes líneas en el fichero ~/.bashrc`:
# >>> conda initialize >>>
# !! Contents within this block are managed by 'conda init' !!
__conda_setup="$('/opt/envhpc/slurm19/rhel7/Miniconda2/4.7.10/bin/conda' 'shell.bash' 'hook' 2> /dev/null)"
if [ $? -eq 0 ]; then
eval "$__conda_setup"
else
if [ -f "/opt/envhpc/slurm19/rhel7/Miniconda2/4.7.10/etc/profile.d/conda.sh" ]; then
. "/opt/envhpc/slurm19/rhel7/Miniconda2/4.7.10/etc/profile.d/conda.sh"
else
export PATH="/opt/envhpc/slurm19/rhel7/Miniconda2/4.7.10/bin:$PATH"
fi
fi
unset __conda_setup
# <<< conda initialize <<<
Para que tenga efecto los cambios, tenemos que salir del nodo de login y volver a entrar. Una vez hecho, ya podremos utilizar conda, instalar paquetes y crear entornos.
Crear un entorno en /data#
Por defecto, Conda creará un entorno e instalará todo el software en el /home del usuario. Este almacenamiento esta limitado en tamaño, así que deberíamos configurar los entornos e instalar el software en la partición de /data. Para hacer esto, simplemente tenemos que especificarle a Conda la ruta:
conda create -p data/myenvironment mysoftware
Collecting package metadata (current_repodata.json): done
Solving environment: done
## Package Plan ##
environment location: /data/vjuidias/myenvironment
...
Y lo activamos de la misma manera, especificando la ruta:
4 11 18
Python#
Utilizar Python en TeideHPC#
Una vez conectados a los nodos de login, disponemos de una versión de Python por defecto, que es la versión 2.6.6. Para ver las versiones de Python disponibles, utilizamos la herramienta de modules:
module ava python
---------------------------------------------- /opt/envhpc/modulefiles/.rhel6 ----------------------------------------------
python/2.7.18/gcc python/3.5.4/gcc python/3.7.9/gcc python/3.8.11/gcc
Para cargar alguna de las versiones es posible que tengamos que cargar algún módulo previamente:
module load python/3.8.11/gcc
python/3.8.11/gcc(10):ERROR:151: Module 'python/3.8.11/gcc' depends on one of the module(s) 'openssl/1.1.1k/gcc'
python/3.8.11/gcc(10):ERROR:102: Tcl command execution failed: prereq openssl/1.1.1k/gcc
Por tanto, cargamos los módulos necesarios, en el orden correspondiente:
module load openssl/1.1.1k/gcc python/3.8.11/gcc
module list
Currently Loaded Modulefiles:
1) openssl/1.1.1k/gcc 2) python/3.8.11/gcc
Ahora podremos utilizar una versión específica de Python y utilizar entornos, donde instalar paquetes de Python de manera aislada.
Instalar paquetes de Python en /data#
Por defecto, Python instalará los paquetes en el /home del usuario. Este almacenamiento esta limitado en tamaño, así que deberíamos configurar los entornos e instalar el software en la partición de /data. Para hacer esto, tenemos que hacer lo siguiente:
Con la opción --target=DIR le indicamos a pip donde se tienen que instalar tanto el paquete solicitado, como todas sus dependencias. Por otro lado, la opción --install-option="--install-scripts=DIR, indica donde irán instalados los binarios, en caso de utilizar el paquete de python desde la línea de comandos directamente.
Luego, tenemos que añadir a nuestro PATH la nueva ruta para utilizar los binarios directamente:
Para hacerlo permanente, podemos añadir esa línea al final de nuestro ~/.bashrc.
R#
R es un lenguaje y un entorno de programación diseñado para trabajar en el ámbito estadístico.
Utilizar R en TeideHPC#
Una vez conectados a los nodos de login, para ver las versiones de R disponibles, utilizamos la herramienta de modules:
module ava R
---------------------------------------------- /opt/envhpc/modulefiles/.rhel6 ----------------------------------------------
R/3.4.4/gcc R/3.6.1/gcc R/4.0.3/gcc R/4.1.1/gcc
Para cargar alguna de las versiones es posible que tengamos que cargar algún módulo previamente:
module load R/4.1.1/gcc
R/4.1.1/gcc(10):ERROR:151: Module 'R/4.1.1/gcc' depends on one of the module(s) 'gcc/10.2.0'
R/4.1.1/gcc(10):ERROR:102: Tcl command execution failed: prereq gcc/10.2.0
Por tanto, cargamos los módulos necesarios, en el orden correspondiente:
module load gcc/10.2.0 R/4.1.1/gcc
module list
Currently Loaded Modulefiles:
1) openssl/1.1.1k/gcc 2) python/3.8.11/gcc 3) gcc/10.2.0 4) R/4.1.1/gcc
Ahora ya podemos empezar a utilizar R:
R
R version 4.1.1 (2021-08-10) -- "Kick Things"
Copyright (C) 2021 The R Foundation for Statistical Computing
Platform: x86_64-pc-linux-gnu (64-bit)
R is free software and comes with ABSOLUTELY NO WARRANTY.
You are welcome to redistribute it under certain conditions.
Type 'license()' or 'licence()' for distribution details.
Natural language support but running in an English locale
R is a collaborative project with many contributors.
Type 'contributors()' for more information and
'citation()' on how to cite R or R packages in publications.
Type 'demo()' for some demos, 'help()' for on-line help, or
'help.start()' for an HTML browser interface to help.
Type 'q()' to quit R.
>
Instalar paquetes de R en /data#
Por defecto, R instalará los paquetes en el /home del usuario. Este almacenamiento esta limitado en tamaño, así que deberíamos configurar los entornos e instalar el software en la partición de /data. Para hacer esto, tenemos que configurar una variable de entorno:
De esta forma, R utilizrá esta ruta como librería por defecto en lugar del /home del usuario. Al utilizar las funciones de R como install.packages() y library(), los paquetes serán instalados en la ruta definida en la variable R_LIBS_USER. Si quiere evitar tener que definir esta variable cada vez que se conecta, puede añadir esa línea al final de su fichero ~/.bashrc, de esta forma, será permanente.
Ejecutar un script de R en Slurm#
Para utilizar un script de R en Slurm, tenemos que ejecutarlo de la siguiente manera:
Jupyter ↵
Jupyter en el Clúster HPC#
Proyecto Jupyter es un proyecto con el objetivo de desarrollar software de código abierto, estándares abiertos y servicios para computación interactiva a través de múltiples lenguajes de programación.
Los Jupyter Notebooks son herramientas web interactivas conocidas como cuadernos computacionales, que los investigadores pueden usar para combinar código de software, texto explicativo y recursos multimedia, y salida computacional, en un solo documento. Jupyter se ha convertido en un estándar de facto para los científicos de datos y otros dominios científicos.
Dentro del proyecto Jupyter se han desarrollado y respaldado los productos informáticos interactivos Jupyter Notebook, JupyterLab y JupyterHub.
Jupyter Notebook: la interfaz de notebook clásica#
Jupyter Notebook es la aplicación web original para crear y compartir documentos computacionales. Ofrece una experiencia simple, optimizada y centrada en documentos.
Es una aplicación de servidor-cliente que permite editar y ejecutar documentos de cuaderno a través de un navegador web. Jupyter Notebook se puede ejecutar en un escritorio local que no requiera acceso a Internet o se puede instalar en un servidor remoto y acceder a través de Internet.
JupyterLab: una interfaz de notebook de próxima generación#
JupyterLab es el último entorno de desarrollo interactivo basado en la web para notebooks, código y datos. Su interfaz flexible permite a los usuarios configurar y organizar flujos de trabajo en ciencia de datos, computación científica, periodismo computacional y aprendizaje automático.
JupyterHub#
JupyterHub lleva el poder de los notebooks a grupos de usuarios. Brinda a los usuarios acceso a entornos y recursos computacionales sin sobrecargar a los usuarios con tareas de instalación y mantenimiento. Los usuarios, incluidos estudiantes, investigadores y científicos de datos, pueden realizar su trabajo en sus propios espacios de trabajo en recursos compartidos que los administradores del sistema pueden administrar de manera eficiente.
JupyterHub se ejecuta en la nube o en su propio hardware y permite brindar un entorno de ciencia de datos preconfigurado a cualquier usuario del mundo. Es personalizable y escalable, y es adecuado para equipos pequeños y grandes, cursos académicos e infraestructura a gran escala.
Ejecución remota de Jupyter Notebook con Slurm#
Como sabemos, Jupyter Notebook se pueden iniciar localmente y acceder a los sistemas de archivos locales, o se pueden iniciar en una máquina remota y que proporcione acceso a los archivos de un usuario en el sistema remoto. En este último caso, Jupyter se inicia a través de un proceso que crea una URL única que se compone del nombre de host más un puerto disponible (elegido por la aplicación jupyter) más un token único. El usuario obtiene esta URL y la ingresa en un navegador web local, donde el servidor de Notebooks está disponible siempre que el proceso en la máquina remota esté activo y en ejecución. Hay que tener en cuenta que de forma predeterminada, estos servidor de Jupyter no es seguro y exponen potencialmente los archivos locales de los usuarios a usuarios no deseados.
Por ello debes tener en cuenta estos conceptos:
No ejecutar Jupyter en los nodos de login
Los nodos de login del clúster es un recurso compartido por muchos usuarios. La ejecución de Jupyter en uno de estos nodos puede afectar negativamente a otros usuarios. Utilice uno de los enfoques descritos en esta página para realizar su trabajo.
Internet no está disponible en los nodos de cómputo
Las sesiones de Jupyter deben ejecutarse en los nodos de cómputo los cuales no tienen acceso a Internet. Esto significa que no podrá descargar archivos, clonar un repositorio de GitHub, instalar paquetes, etc. Deberá realizar estas operaciones en los nodos de login. Cualquier archivo que descargue mientras está en el nodo de login estará disponible inmediatamente en los nodos de cómputo durante la sesión.
No puede acceder directamente a los nodos de cómputo
Por motivos de seguridad, no se puede acceder directamente a los nodos de cálculo. Sin embargo, se puede acceder a ellos mientras ejecuta un trabajo desde cualquier nodo de login.
Esta implementación no es el servidor multiusuario que andas buscando
Este documento describe cómo puede ejecutar un servidor público con un solo usuario. Esto solo debe hacerlo alguien que quiera acceder de forma remota a su cuenta personal. Aun así, hacer esto requiere una comprensión profunda de las limitaciones de las configuraciones y las implicaciones de seguridad. Si permite que varios usuarios accedan a un servidor portátil como se describe en este documento, sus comandos pueden colisionar, aplastarse y sobrescribirse entre sí.
Si quieres un servidor multiusuario, la solución oficial es JupyterHub. Para usar JupyterHub, necesita un servidor Unix (generalmente Linux) que se ejecute en algún lugar al que puedan acceder sus usuarios en una red. Esto puede ejecutarse a través de Internet público, pero hacerlo presenta problemas de seguridad adicionales.
Crear un entorno conda#
En primer lugar tenemos que crear un entorno conda. Puede ver estos pasos [aquí] (how_to_conda.md).
Recordar:
-
Use nodos de inicio de sesión para crear un entorno python/conda. Sólo estos tienen acceso a internet.
$ module spider miniconda
$ module load Miniconda3/4.9.2
$ conda create --name jupyter-env [python=3.9.15] or
$ conda create --prefix /home/user/data/allenvironments/my_environtment [python=3.9.15]
Collecting package metadata (current_repodata.json): done
Solving environment: done
….
# To activate this environment, use
# $ conda activate jupyter-env
# To deactivate an active environment, use
# $ conda deactivate
- Instalar los paquetes necesarios para Jupyter Notebooks
conda activate jupyter-env
conda install jupyter ipykernel matplotlib ipywidgets ipympl --channel conda-forge -y
Ejecutar Jupyter Notebook en un nodo de cómputo mediante salloc#
Las tareas más grandes se pueden ejecutar en uno de los nodos de cómputo solicitando una sesión interactiva usando salloc.
Lo primero es lo primero: inicia una sesión de screen (o tmux si lo prefieres). Si busca tener un programa ejecutándose por más tiempo del que quiero mantener abierta una ventana de terminal, screen o tmux son excelentes opciones, ya que evitan que su sesión se agote en máquinas remotas.
screen -S jupyter
salloc --nodes=1 --partition batch --ntasks=1 --mem=20G --time=12:00:00
# or salloc -N 1 -p batch
# or srun -p batch --pty bash
conda activate jupyter-env
Ahora debería ver que el indicador de su terminal ha cambiado a algo como lo siguiente, lo que indica que ha iniciado sesión interactiva un nodo de cómputo y está trabajando dentro del entorno conda-env:
Una vez que se ha asignado un nodo de cómputo, inicia Jupyter. En el nodo de cómputo ejecuta:
Jupyter Notebook se inician a través de un proceso que crea una URL única que se compone de ip y puerto 8889 más un token de un solo uso. El usuario obtiene esta URL y la ingresa en un navegador web local, donde el servidor está disponible siempre que el proceso en la máquina remota esté activo y en ejecución.
[I 13:22:01.198 NotebookApp] Writing notebook server cookie secret to /home/youruser/.local/share/jupyter/runtime/notebook_cookie_secret
[I 13:22:12.448 NotebookApp] Serving notebooks from local directory: /home/youruser
[I 13:22:12.448 NotebookApp] Jupyter Notebook 6.5.2 is running at:
[I 13:22:12.448 NotebookApp] http://127.0.0.1:8889/?token=36229e08e0944c8d1b4df0174e23a7ee11e278ccbed5f967
[I 13:22:12.448 NotebookApp] or http://127.0.0.1:8889/?token=36229e08e0944c8d1b4df0174e23a7ee11e278ccbed5f967
[I 13:22:12.448 NotebookApp] Use Control-C to stop this server and shut down all kernels (twice to skip confirmation). [C 13:22:12.568 NotebookApp]
To access the notebook, open this file in a browser:
file:///home/youruser/.local/share/jupyter/runtime/nbserver-4762-open.html
Or copy and paste one of these URLs:
http://127.0.0.1:8889/?token=36229e08e0944c8d1b4df0174e23a7ee11e278ccbed5f967
or http://127.0.0.1:8889/?token=36229e08e0944c8d1b4df0174e23a7ee11e278ccbed5f967
Tip
Tenga en cuenta que de forma predeterminada Jupyter Notebook abre automáticamente un navegador, pero no podemos hacerlo en un nodo de cómputo directamente por seguridad, por lo que omitimos esa función con el indicador --no-browser.
Tip
Tenga en cuenta que seleccionamos el puerto Linux 8889 para conectarse al servidor de Notebook. Si no especifica el puerto, se establecerá de forma predeterminada en el puerto 8888, pero a veces este puerto puede estar ya en uso en la máquina remota o en la local (es decir, su PC). Si el puerto que seleccionó no está disponible, recibirá un mensaje de error, en cuyo caso debe elegir otro. Es mejor seleccionar un puerto mayor al 1024. Considere comenzar con 8888 e incrementarlo en 1 si falla, por ejemplo, intente 8888, 8889, 8890 y así sucesivamente. Si está ejecutando en un puerto diferente, sustituya su número de puerto por 8889.
Por defecto, Jupyter Notebooks no es seguro y potencialmente exponen sus archivos a usuarios no deseados.
Ejecutar Notebook de la forma habitual utiliza conexiones HTTP inseguras. En esta guía, presentamos una guía para ejecutarlo de forma más segura.
Crear un tunnel SSH#
Por razones de seguridad, recomendamos usar túneles ssh para conectarse de forma segura al servidor de Jupyter Notebook. Con esto creará una conexión ssh entre su host local y el puerto del servidor de Notebook ejecutándose en el nodo interactivo remoto. Cuando conecte su navegador al servicio de notebook, este canalizará todas las comunicaciones a través de la conexión SSH, que es segura y encriptada.
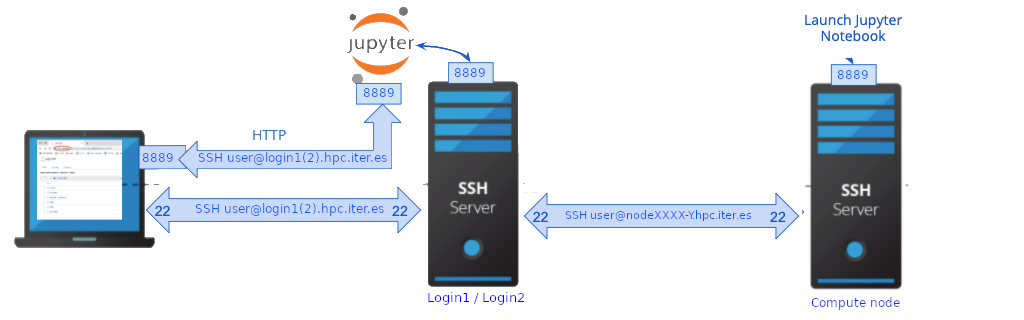
Inicie una segunda sesión de terminal en su máquina local, conéctese a cualquier nodo de login y configure el túnel SSH de la siguiente manera:
En el nodo de login escribir:
Podrias ver un mensaje de este tipo:
The authenticity of host 'node1710-1.hpc.iter.es (10.0.17.37)' can't be established.
ECDSA key fingerprint is SHA256:LqRpSE90hft08tO47V2nx7jbIsUOX42SeKAgEVBPODo.
Are you sure you want to continue connecting (yes/no/[fingerprint])? yes
Warning: Permanently added 'node1710-1.hpc.iter.es' (ECDSA) to the list of known hosts.
Inicia un tercera consola en tu ordenador personal y establece el tunnel hacia el nodo de login de la siguiente manera.
-N No ejecuta un comando remoto. Útil sólo para reenviar puertos.
-L Especifica que el puerto dado en el host local (cliente) se reenviará al puerto dado host y puerto en el lado remoto.
Puedes usar los DNS o las IPs de los nodos
Sólo hay que cambiar nodeXXXX-X.hpc.iter.es por la IP del nodo.
Finalmente, copie y pegue la dirección en su navegador favorito y reemplace la parte “?token=x” de la URL con su token
Recomendamos leer sa sección Notas importantes below.
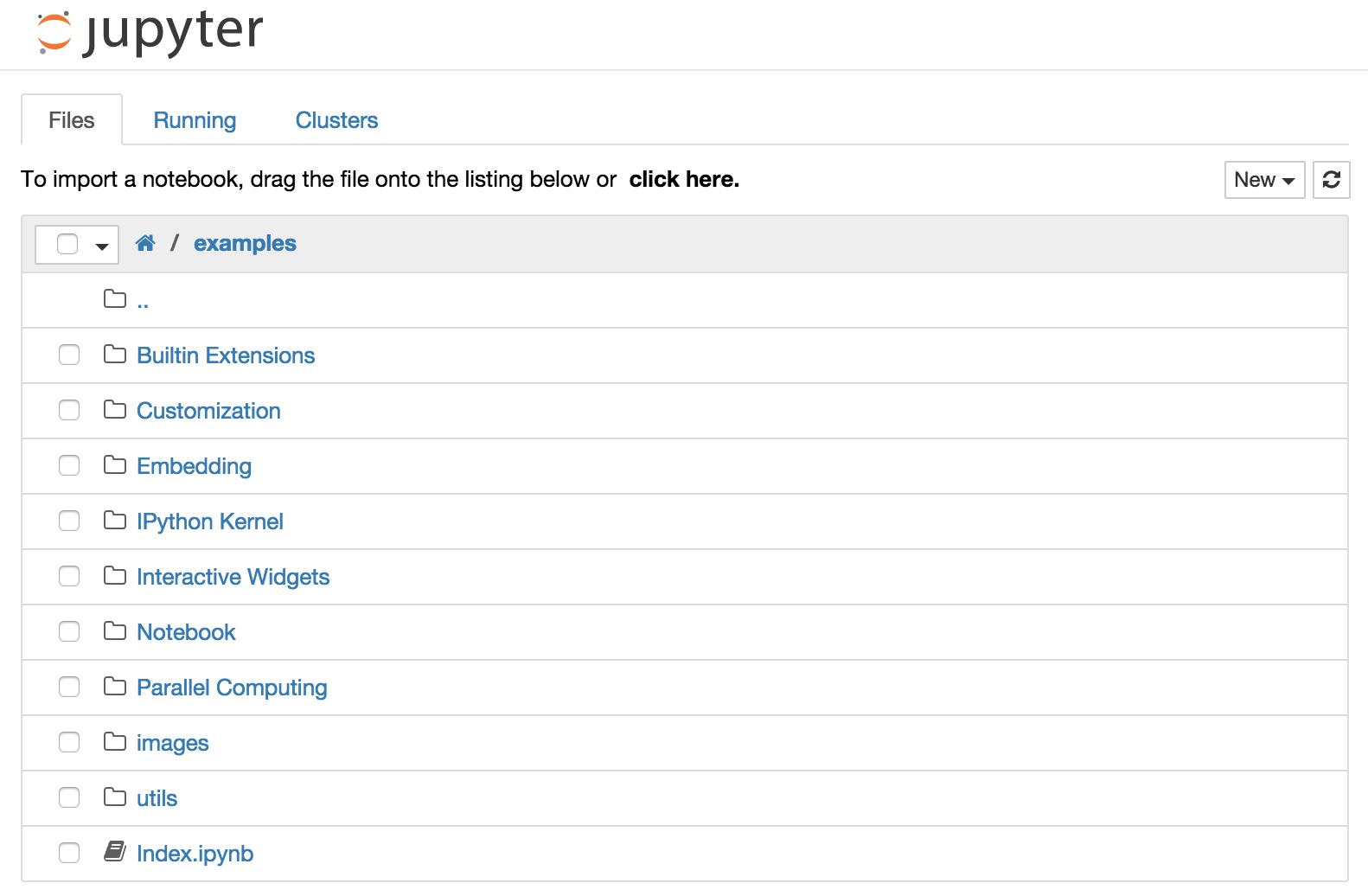
Running Jupiter Notebook on a Compute Node via sbatch#
La segunda forma de ejecutar Jupyter en el clúster es enviando un trabajo a mediante el commando sbatch.
Para hacer esto, necesitamos un script de envío como el siguiente que podemos llamar jupyter.sh:
#!/bin/bash
#SBATCH --nodes=1
#SBATCH --ntasks=1
#SBATCH --cpus-per-task=1
#SBATCH --mem=20G
#SBATCH --partition=batch
#SBATCH --constrains=sandy
#SBATCH --time=01:00:00
#SBATCH --job-name=jupyter-notebook
#SBATCH --output=jupyter-notebook-%j.out
#SBATCH --error=jupyter-notebook-%j.err
##########################################################
# Enable modules profile
# Enable conda on bash console
eval "$(conda shell.bash hook)"
# load modules or conda environments here
module load Miniconda3/4.9.2
conda activate jupyter-env
# get tunneling info
XDG_RUNTIME_DIR=""
node=$(hostname -s)
user=$(whoami)
cluster="teide-hpc"
port=8889
# print tunneling instructions jupyter-log
echo -e "
Command to create ssh tunnel from login node to compute node:
ssh -N -L localhost:${port}:localhost:${port} ${user}@nodeXXXX-Y.hpc.iter.es
Command to create ssh tunnel from your local machine to any login node:
ssh -N -L localhost:${port}:localhost:${port} ${user}@login1(2).hpc.iter.es
Use a Browser on your local machine to go to:
localhost:${port} (prefix w/ https:// if using password)
"
# Run Jupyter
jupyter-notebook --no-browser --port=${port} --ip=127.0.0.1
Este trabajo inicia Jupyter en el nodo de cómputo asignado y podemos acceder a él a través de un túnel ssh como lo hicimos en la sección anterior.
Enviamos el trabajo a la cola:
Una vez que se ejecuta el trabajo, se creará un log llamado jupyter-notebook-
Para conectarse a Jupyter que se ejecuta en el nodo de cómputo, configure un túnel entre el nodo de cómputo y el nodo de inicio de sesión como:
y entre su máquina local y el nodo de login:
Para acceder a Jupyter Notebook, navegue http://localhost:8889/
Notas Importantes#
Establecer una contraseña segura en Jupyter Notebook
Antes de conectarse a un servidor remoto con jupyter notebook, asegúrese de haber configurado jupyter con información de contraseña. Puede hacerlo editando jupyter-notebook_config.json que generalmente se encuentra en ~/.jupyter o escribiendo:
Enter password:
Verify password:
[NotebookPasswordApp] Wrote hashed password to /home/yourUser/.jupyter/jupyter_notebook_config.json
Cómo cambiar el directorio de inicio de Jupyter Notebook
De forma predeterminada, Jupyter usa su hogar como directorio de inicio predeterminado, pero es posible cambiarlo mediante dos métodos:
- Usando el argumento –notebook-dir:
-
Cambiar el directorio predeterminado generando un archivo de configuración
-
Escriba el siguiente comando para crear una carpeta de configuración.
- Abra el archivo ~/.jupyter/jupyter_notebook_config.py*.
- Busque el comentario, The directory to use for notebooks and kernels
- Descomente y reemplace la siguiente propiedad en el archivo con su directorio preferido.
- Vuelva a ejecutar Jupyter Notebook.
Asegúrese de cerrar su servidor de Jupyter cuando haya terminado
Para hacer esto, si está utilizando el modo salloc, puede volver a iniciar sesión en la sesión de screen que inició anteriormente donde se ejecuta el cuaderno jupyter y use ctrl-C para cerrar el cuaderno jupyter y salir para cerrar la sesión con el nodo.
Si está utilizando el sbatch, puede usar el comando scancel
Conceptos básicos de Jupyter Notebook#
En el siguiente enlace puede encontrar una descripción de Jupyter Notebooks:
El dashboard Notebook#
Ejemplo básico#
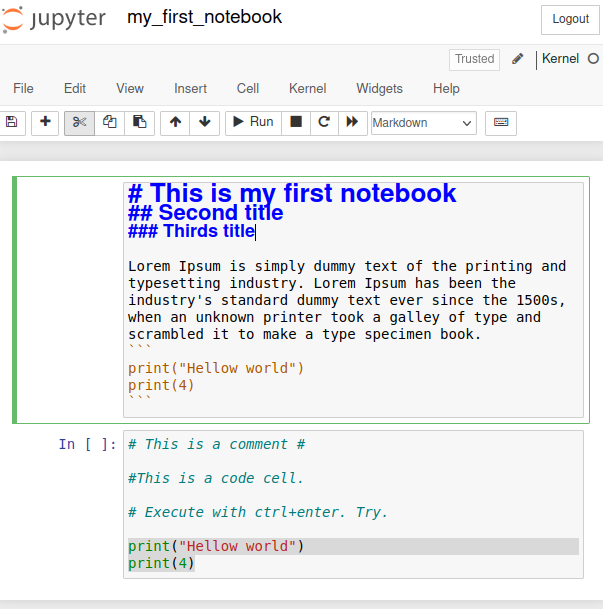
Ejecutar de un Notebook#
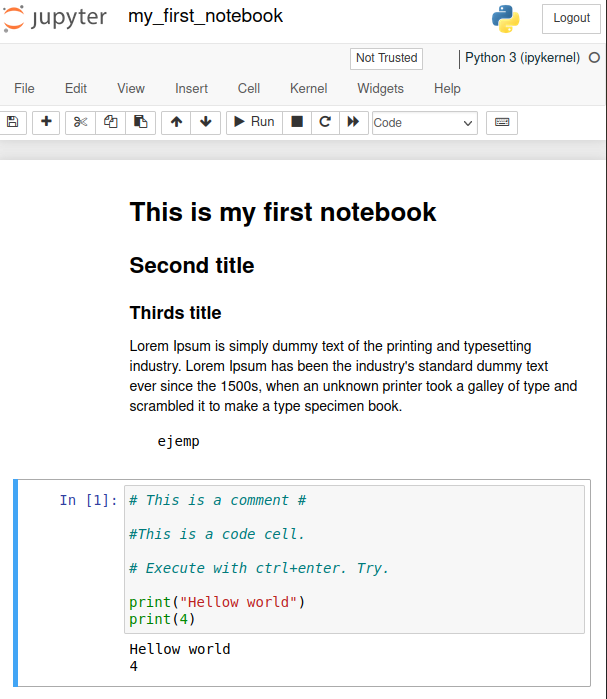
JupyterLab: La evolución de Jupyter Notebook#
JupyterLab es la interfaz de usuario nueva generación para el proyecto Jupyter. Básicamente es un IDE con todas las funciones que tiene todo lo que siempre se quiso tener en los notebooks de Jupyter que le permite trabajar con documentos y actividades tal y como en Notebook, además de editores de texto, terminales y componentes personalizados de manera flexible, integrada y extensible.
Las principales características de JupyterLab son:
- Arrastrar y soltar:
La capacidad de reordenar celdas sin cortar y pegar es poderosa. También se siente más natural arrastrar y soltar dado que el código está organizado en celdas en notebooks.
- Múltiples notebooks y kernels:
La ejecución de varios notebooks al mismo tiempo ya existe con los Juypyter Notebook. Sin embargo, estos notebooks tenían que abrirse en varias ventanas del navegador. En JupyterLab, puede tener varios notebooks abiertos al mismo tiempo y en la misma ventana del navegador. Además, puede organizar sus Notebook como desee, lo que le brinda más flexibilidad. Otra buena característica es que es posible hacer que cada notebook se ejecute en su propio kernel, esto es poderoso cuando se ejecutan varios notebooks al mismo tiempo haciendo cosas diferentes.
- Editor de markdown en tiempo real
Con esta nueva función, puedo editar y ver en tiempo real la actualización de mis archivos markdown en JupyterLab. Esto acelera el proceso de edición y agiliza el trabajo.
- Múltiples ventanas
Con varias ventanas abiertas al mismo tiempo, puedo tener varios notebooks en las que estoy trabajando y luego usar una terminal dentro de JupyterLab
- Explorador de archivos completo
El explorador de archivos y el menú Archivo le permiten trabajar con archivos y directorios en su sistema. Esto incluye abrir, crear, eliminar, renombrar, descargar, copiar y compartir archivos y directorios.
- Gestionar distintos kernel y terminales
- Búsqueda de comandos
- Visor rápido de archivos CSV
- ...
Ejecutar JupyterLab de forma remota con Slurm#
Al igual que Jupyter Notebook, JupyterLab se puede iniciar localmente y acceder a los archivos locales, o se pueden iniciar en una máquina remota.
De forma predeterminada, Labs no es seguro y potencialmente expone los archivos locales de los usuarios a usuarios no deseados. Recomendamos leer la sección Ejecutar Jupyter Notebook con Slurm donde puede encontrar varios consejos para usar Jupyter Notebook y que son de aplicación a JupyterLab.
Recuerda:
No ejecute Jupyter en los nodos de login
Internet no está disponible en los nodos de cómputo
No se puede acceder directamente a los nodos de cómputo
Esta implementación no es el servidor multiusuario que andas buscando
Puede utilizar JupiterLab de dos maneras diferentes:
- Crear un entorno conda o pip
- Uso como módulo
Crear un entorno Conda para instalar JupyterLab#
Crear un entorno Conda
Aquí tenemos varias recomendaciones para trabajar con entornos de conda que recomendamos leer. Para simplificar:
Usar JupyterLab como módulo#
Para buscar el módulo escribir:
------------------------------------------------------------------
JupyterLab: JupyterLab/3.1.6
------------------------------------------------------------------
Description:
JupyterLab is the next-generation user interface for Project Jupyter offering all the familiar building blocks of the classic Jupyter Notebook (notebook, terminal, text editor, file browser, rich outputs, etc.) in a flexible and powerful user interface.
JupyterLab will eventually replace the classic Jupyter Notebook.
You will need to load all module(s) on any one of the lines below before the "JupyterLab/3.1.6" module is available to load.
GCCcore/11.2.0
...
Cómo iniciar JupyterLab#
Depende de cómo quieras iniciarlo. Si prefieres usarlo como módulo sólo tienes que cambiar la línea que activa el entorno por la que carga el módulo.
with
Ejecutar JupyterLab en un nodo de cómputo mediante salloc#
salloc --nodes=1 --partition batch --ntasks=1 --mem=20G --time=12:00:00
# or salloc -N 1 -p batch
# or srun -p batch --pty bash
conda activate jupyter-labenv
jupyter lab --no-browser --port=8890 --ip=127.0.0.1
Por defecto JupyterLab no es seguro y expone sus archivos locales a usuarios no deseados.
Ejecutar Labs de la forma habitual utiliza conexiones HTTP inseguras. En esta guía, presentamos una guía para ejecutarlo de forma más segura. Más info aquí
Tip
Tenga en cuenta que el valor predeterminado es que JupyterLab abra automáticamente un navegador, pero no podemos hacerlo en un servidor remoto, por lo que omitimos esa función con el parámetro --no-browser).
Crear túnel SSH#
Aquí hablamos sobre las razones por las que es necesario crear el túnel ssh y cómo hacerlo.
Inicia una segunda terminal, conecta a uno de los nodos de login y ejecuta crea un tunel entre el nodo login y el de ejecución.
En tu máquina local, establece el tunel contra el nodo de login como a continuación:
!!! tip "Puedes usar los DNS del nodo o la IP
Change _nodeXXXX-X.hpc.iter.es_ or loginX.hpc.iter.es by node ip.
Introduce la dirección que te da Lab en tu navegador favorito
http://127.0.0.1:8890/lab?token=4c7eddd5770e27195808f4615d8e6f3de48b45c57169b69e
Ejecutar JupyterLab en un nodo de cómputo mediante sbatch#
#!/bin/bash
#SBATCH --nodes=1
#SBATCH --ntasks=1
#SBATCH --cpus-per-task=1
#SBATCH --mem=20G
#SBATCH --partition=batch
#SBATCH --constrains=sandy # sandy, ilk (icelake)... arquitecture
#SBATCH --time=01:00:00
#SBATCH --job-name=jupyter-lab
#SBATCH --output=jupyter-lab-%j.out
#SBATCH --error=jupyter-lab-%j.err
##########################################################
# Enable modules profile
# Enable conda on bash console
eval "$(conda shell.bash hook)"
# load modules or conda environments here
module load Miniconda3/4.9.2
conda activate jupyter-labenv
# get tunneling info
XDG_RUNTIME_DIR=""
node=$(hostname -s)
user=$(whoami)
cluster="teide-hpc"
port=8890
# print tunneling instructions jupyter-log
echo -e "
Command to create ssh tunnel from login node to compute node:
ssh -N -L localhost:${port}:localhost:${port} ${user}@nodeXXXX-Y.hpc.iter.es
Command to create ssh tunnel from your local machine to any login node:
ssh -N -L localhost:${port}:localhost:${port} ${user}@login1(2).hpc.iter.es
Use a Browser on your local machine to go to:
localhost:${port} (prefix w/ https:// if using password)
"
# Run Jupyter
jupyter lab --no-browser --port=${port} --ip=127.0.0.1
Para ejecutarlo
Para acceder a JupyterLab navegar a http://localhost:8890/
Notas importantes#
Establecer una contraseña segura en JupyterLab
De forma predeterminada, Lab inicia el servidor con la autenticación de token habilitada y este token se registra en el terminal, de modo que puede copiar y pegar la URL en su navegador. Este token se puede usar sólo una vez y se usa para configurar una cookie para su navegador una vez que se conecta. Después de que su navegador haya realizado su primera solicitud con este token único, el token se descarta y se establece una cookie en su navegador.
Como alternativa a la autenticación por token puede establecer una contraseña para su servidor. En posteriores inicios se le pedirá una contraseña y esta se almacenará cifrada en su archivo de configuración jupyter_server_config.json que generalmente se encuentra en ~/.jupyter. Puede configurar su contraseña escribiendo:
Enter password:
Verify password:
[JupyterPasswordApp] Wrote hashed password to /home/vdominguez/.jupyter/jupyter_server_config.json
Más consejos de seguridad aquí
Cómo cambiar el directorio de inicio de Jupyter
Si los archivos de su notebook no están en el directorio donde está ejecutando Jupyter, puede pasar la ruta del directorio de trabajo como argumento al iniciar JupyterLab de la siguiente forma:
Hay que tener en cuenta que la sesión de Jupyter siempre reside en un workspace. El workspace por defecto es la URL /lab :bash http(s)://<server:port>/<lab-location>/lab
Asegúrese de cerrar JupyterLab cuando haya terminado
Para hacer esto, si está utilizando el modo salloc, puede volver a iniciar sesión en la sesión de screen que inició anteriormente donde se ejecuta el cuaderno jupyter y use ctrl-C para cerrar el servidor de Jupyter y exit para cerrar la sesión con el nodo.
Si está utilizando el modo sbatch, puede usar el comando scancel
JupyterLab Extensions Manager#
El gestor de extensiones de JupyterLab es simplemente un complemento plug-and-play que hace posibles más cosas que puede que necesite.
Técnicamente, la extensión JupyterLab es un paquete de JavaScript que puede agregar todo tipo de características interactivas a la interfaz de JupyterLab.
Hay un montón de extensiones de JupyterLab que tal vez quieras usar. Entre las más conocidas podemos destacar:
Jupyterlab-slurm#
Una extensión de JupyterLab para interactuar con el administrador de carga de trabajo de Slurm.
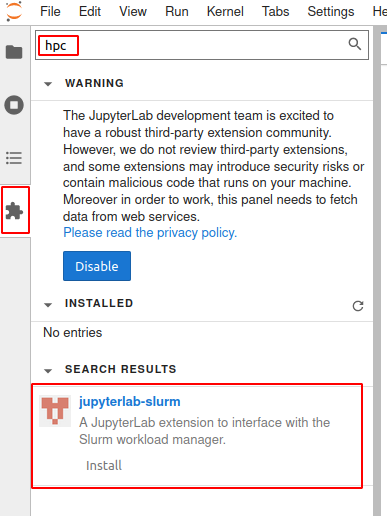
Neptune-notebooks#
Neptune es una herramienta para el seguimiento de experimentos, el registro de modelos, el control de versiones de datos y la supervisión de modelos en vivo.
JupyterLab TensorBoard#
JupyterLab TensorBoard es una extensión de interfaz para tensorboard en jupyterlab. Ayuda a colaborar entre jupyter notebook y tensorboard (una herramienta de visualización para tensorflow) al proporcionar una interfaz gráfica de usuario para iniciar, administrar y detener tensorboard en la interfaz de jupyter.
Jupyter ML-workspace#
ML workspace es un entorno de desarrollo integrado todo en uno basado en la web dedicado al aprendizaje automático y la ciencia de datos.
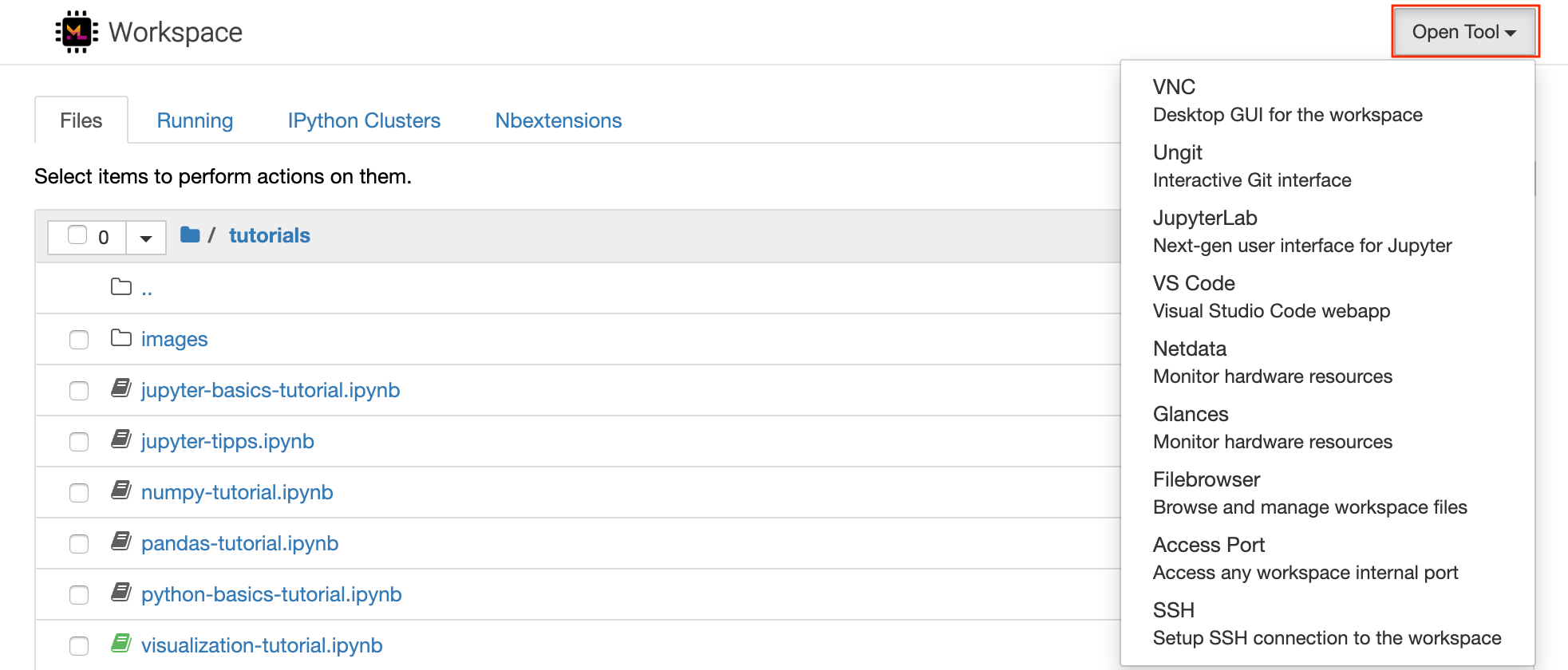
JupyterLab Debugger#
Debugger es una extensión de JupyterLab que funciona como un depurador visual para notebooks, consolas y archivos fuente de Jupyter. Puede ayudarlo a identificar y corregir errores.
JupyterLab Git#
Esta es una extensión de JupyterLab para Git, un sistema de control de versiones distribuido gratuito y de código abierto. Le permite controlar la versión. Simplemente lo usa abriendo la extensión Git desde la pestaña Git en el panel izquierdo.
Otras extensiones destacables:
- JupyterLab LaTeX
- JupyterLab variableInspector
- JupyterLab plotly
- JupyterLab bokeh
- Jupyter Dash
- JupyterLab Table of Contents
- JupyterLab SQL
JupyterHub#
Como decíamos en páginas previas, JupyterHub ofrece el poder de los Jupyter Notebook a grupos de usuarios. Si crees que es realmente lo que necesitas, contactanos por email en support@hpc.iter.es.
Ended: Jupyter
Singularity#
Singurlaity es una plataforma que permite la ejecución de contenedores en entornos HPC. Docker es la herramienta más popular para ejecutar aplicaciones en contenedores, pero tal y como está diseñado, ponerlo en producción con la posibilidad de que sean los propios usuarios quiénes gestionen los contenedores, supone un riesgo de seguridad muy importante. Es por eso que nacieron alternativas como Singularity y otras.
Singularity cuenta con soporte para utilizar MPI y GPU para ejecutar contendores y se pueden integrar en un script de Slurm sin problemas.
Utilizar Singularity en TeideHPC#
Info
Actualmente disponemos de la versión v3.11 en TeideHPC.
Utilizando la herramienta de modules podemos cargar el software:
$ module load Singularity/3.11.0
$ singularity -h
Linux container platform optimized for High Performance Computing (HPC) and
Enterprise Performance Computing (EPC)
Usage:
singularity [global options...]
Description:
Singularity containers provide an application virtualization layer enabling
mobility of compute via both application and environment portability. With
Singularity one is capable of building a root file system that runs on any
other Linux system where Singularity is installed.
Options:
-c, --config string specify a configuration file (for root or
unprivileged installation only) (default
"/share/easybuild/software/common/software/Singularity/3.11.0/etc/singularity/singularity.conf")
-d, --debug print debugging information (highest verbosity)
-h, --help help for singularity
--nocolor print without color output (default False)
-q, --quiet suppress normal output
-s, --silent only print errors
-v, --verbose print additional information
--version version for singularity
Available Commands:
build Build a Singularity image
cache Manage the local cache
capability Manage Linux capabilities for users and groups
completion Generate the autocompletion script for the specified shell
config Manage various singularity configuration (root user only)
delete Deletes requested image from the library
exec Run a command within a container
help Help about any command
inspect Show metadata for an image
instance Manage containers running as services
key Manage OpenPGP keys
oci Manage OCI containers
overlay Manage an EXT3 writable overlay image
plugin Manage Singularity plugins
pull Pull an image from a URI
push Upload image to the provided URI
remote Manage singularity remote endpoints, keyservers and OCI/Docker registry credentials
run Run the user-defined default command within a container
run-help Show the user-defined help for an image
search Search a Container Library for images
shell Run a shell within a container
sif Manipulate Singularity Image Format (SIF) images
sign Add digital signature(s) to an image
test Run the user-defined tests within a container
verify Verify digital signature(s) within an image
version Show the version for Singularity
Examples:
$ singularity help <command> [<subcommand>]
$ singularity help build
$ singularity help instance start
For additional help or support, please visit https://www.sylabs.io/docs/
Contenedores Docker#
Singularity utiliza su propio formato de contenedores, .sif, teniendo que transformar los contenedores de Docker para que puedan ser utilizados, pero es algo que hace el propio programa sin necesidad de que el usuario tenga que intervenir.
Descargar un contenedor desde DockerHUB#
Info
A la hora de descargar contenedores hay que hacerlo siempre desde los nodos de login que son los que tienen acceso a Internet y no desde los de cómputo.
En este ejemplo descargaremos una imagen desde DockerHub para ser utilizada en el clúster:
singularity pull docker://hello-world
INFO: Converting OCI blobs to SIF format
INFO: Starting build...
Getting image source signatures
Copying blob 8a49fdb3b6a5 done
Copying config 689808b082 done
Writing manifest to image destination
Storing signatures
2023/06/01 15:06:41 info unpack layer: sha256:8a49fdb3b6a5ff2bd8ec6a86c05b2922a0f7454579ecc07637e94dfd1d0639b6
INFO: Creating SIF file...
Nos descargará el archivo de la imagen del contenedor en el directorio actual:
Si queremos, al igual que hacemos con docker, podemos especificar una versión en concreto:
Una vez descargado, podríamos probar a ejecutar el contenedor:
Warning
Recordamos a los usuarios que no se puede ejecutar software en los nodos de login y esto inluye contendores. Para ello, tienen disponible el comando de slurm salloc para solicitar un nodo de manera interactiva y poder trabajar sin problemas.
singularity run hello-world_latest.sif
INFO: Converting SIF file to temporary sandbox...
WARNING: passwd file doesn't exist in container, not updating
WARNING: group file doesn't exist in container, not updating
Hello from Docker!
This message shows that your installation appears to be working correctly.
To generate this message, Docker took the following steps:
1. The Docker client contacted the Docker daemon.
2. The Docker daemon pulled the "hello-world" image from the Docker Hub.
(amd64)
3. The Docker daemon created a new container from that image which runs the
executable that produces the output you are currently reading.
4. The Docker daemon streamed that output to the Docker client, which sent it
to your terminal.
To try something more ambitious, you can run an Ubuntu container with:
$ docker run -it ubuntu bash
Share images, automate workflows, and more with a free Docker ID:
https://hub.docker.com/
For more examples and ideas, visit:
https://docs.docker.com/get-started/
INFO: Cleaning up image...
En caso de necesitarlo, también disponemos del comando build para descargar contenedores de docker. La utilidad principal del comando build está en poder crear nuestros propios contenedores a partir de otros ya existentes o a partir de un fichero de definición.
singularity build tutu.sif docker://hello-world
INFO: Starting build...
2023/06/01 14:58:33 info unpack layer: sha256:719385e32844401d57ecfd3eacab360bf551a1491c05b85806ed8f1b08d792f6
INFO: Creating SIF file...
INFO: Build complete: tutu.sif
Y lo ejecutaríamos de la misma manera:
singularity run tutu.sif
INFO: Converting SIF file to temporary sandbox...
WARNING: passwd file doesn't exist in container, not updating
WARNING: group file doesn't exist in container, not updating
Hello from Docker!
This message shows that your installation appears to be working correctly.
To generate this message, Docker took the following steps:
1. The Docker client contacted the Docker daemon.
2. The Docker daemon pulled the "hello-world" image from the Docker Hub.
(amd64)
3. The Docker daemon created a new container from that image which runs the
executable that produces the output you are currently reading.
4. The Docker daemon streamed that output to the Docker client, which sent it
to your terminal.
To try something more ambitious, you can run an Ubuntu container with:
$ docker run -it ubuntu bash
Share images, automate workflows, and more with a free Docker ID:
https://hub.docker.com/
For more examples and ideas, visit:
https://docs.docker.com/get-started/
INFO: Cleaning up image...
Si por lo que sea nuestra apliación no está disponible en DockerHub y tenemos que construir el contenedor desde la fuente, lo podemos hacer en nuestro ordenador local, utilizando docker, y luego subir esa imange de Docker a nuestro /home en TeideHPC y crear el contenedor con singularity.
Ejecución de un contenedor#
Como se ha visto, para ejecutar un contenedor con singularity tenemos el comando run:
Pero también podemos ejecutar un contenedor pasándole un comando que se ejecute dentro de éste y argumentos:
singularity exec mycontainer.sif <command> <arg-1> <arg-2> ... <arg-N>
singularity exec tutu.sif python3 myscript.py 42
También podemos trabajar con el contenedor de manera interactiva al igual que hacemos con los contenedores de Docker. Para esto tenemos el comando shell:
singularity shell alpine_latest.sif
INFO: Converting SIF file to temporary sandbox...
Singularity> cat /etc/os-release
NAME="Alpine Linux"
ID=alpine
VERSION_ID=3.18.0
PRETTY_NAME="Alpine Linux v3.18"
HOME_URL="https://alpinelinux.org/"
BUG_REPORT_URL="https://gitlab.alpinelinux.org/alpine/aports/-/issues"
Singularity> pwd
/home/vjuidias
Singularity> exit
INFO: Cleaning up image...
Como vemos, podemos trabajar con el entorno del contenedor, pero seguimos en nuestro directorio, muy útil si queremos para trabajar con ficheros sin necesidad de copiarlos al contenedor.
Ejecutar un contenedor en Slurm#
Para ejecutar singularity en slurm se ejecuta como cualquier otro software, cargando el módulo correspondiente y ejecutándolo:
#!/bin/bash -l
# Job name
#SBATCH -J singularity_job
# Partitiion to run the job
#SBATCH -p batch
# Number of nodes
#SBATCH --nodes=1
# Output files
#SBATCH -o out.log
#SBATCH -e err.log
##############################################################################
module load Singularity/3.11.0
singularity run $HOME/hello-world_latest.sif
Slurm tratará singularity como un software más, es decir, que le aplicará las mismas restricciones de recursos, en cuanto a cpu, memoria y tiempo que el resto del software.
MPI#
Tip
El soporte para MPI dependerá del software que vayamos a ejecutar, no de Singularity. Por tanto, pedimos a los usuarios que lean la documentación de su software detenidamente antes de ejecutar cualquier cosa.
Para poder utilizar MPI con singularity tenemos que cargar el módulo correspondiente y utilizar el comando de srun:
#!/bin/bash -l
# Job name
#SBATCH -J singularity_mpi
# Partitiion to run the job
#SBATCH -p batch
# Number of nodes
#SBATCH --nodes=2
# Output files
#SBATCH -o out.log
#SBATCH -e err.log
##############################################################################
module purge
module load Singularity/3.11.0
module load GCC/12.2.0 OpenMPI/4.1.4
srun singularity run $HOME/hello-world_latest.sif
GPU#
Tip
El soporte para GPU dependerá del software que vayamos a ejecutar, no de Singularity. Por tanto, pedimos a los usuarios que lean la documentación de su software detenidamente antes de ejecutar cualquier cosa.
Para utilizar GPU en la ejecución del software hay que utilizar el parámetro --nv:
Y para el caso de Slurm sería:
#!/bin/bash -l
# Job name
#SBATCH -J singularity_gpu
# Partitiion to run the job
#SBATCH -p gpu
# Number of nodes
##SBATCH --nodes=1
# Number of task
#SBATCH --cpus-per-task=4
#SBATCH --gpus=a100:1
# Output files
#SBATCH -o out.log
#SBATCH -e err.log
##############################################################################
module purge
module load Singularity/3.11.0
singularity run --nv $HOME/hello-world_latest.sif
Otras opciones#
Al igual que con docker, tenemos la opción -B con la que podemos hacer un bind de un directorio de la máquina host en un directorio del contenedor:
Ended: Guías de uso
Ended: Software y herramientas
Infraestructura en la nube (IaaS) ↵
OpenNebula ↵
Infraestructura como Servicio (IaaS)#
IaaS (Infraestructure as a Service) es un modelo de pago por uso, escalable en función de las necesidades de almacenamiento y procesamiento. Proporciona infraestructuras de forma rápida y económica. El cliente paga exclusivamente por los servicios que utilice, sin realizar potentes inversiones en equipamiento de IT. Permite a las empresas aumentar la eficiencia, redundancia, seguridad y control de sus infraestructuras pero olvidándose de su instalación y mantenimiento de la cual se encarga TeideHPC.
Un proveedor de servicios informáticos en la nube, como TeideHPC, administra la infraestructura, mientras que usted compra, instala, configura y administra su propio software (sistemas operativos, middleware y aplicaciones).
Como características principales se pueden destacar las siguientes:
-
En lugar de adquirir hardware directamente, los usuarios pagan por IaaS bajo demanda.
-
La infraestructura es escalable, en función de las necesidades de almacenamiento y procesamiento.
-
Ahorra a las empresas el coste de comprar y mantener su propio hardware.
OpenNebula#
Es una plataforma cloud computing para administrar infraestructuras centro de datos heterogéneas distribuidas. La plataforma OpenNebula (ONE) gestiona la infraestructura virtual de un centro de datos para construir implementaciones privadas, públicas e híbridas de infraestructura como servicio (IaaS).
Acceso a OpenNebula#
Después de conectarse al servidor VPN de TeideHPC, se le proporcionará una ruta de red privada para acceder a la interfaz web de OpenNebula donde podrá gestionar sus máquinas virtuales.
Recuerde
Para acceder a cualquier dominio de TeideHPC como one.iter.es debe estar conectado a la VPN
Interfaz de OpenNebula#
Después de iniciar sesión, la vista predeterminada brinda información sobre las máquinas virtuales (VM) y las cuotas del usuario.

El menú de máquinas virtuales proporciona información sobre las máquinas virtuales realmente definidas.
El menú Plantillas enumera las plantillas creadas a partir de máquinas virtuales que se utilizarán como fuente para nuevas máquinas virtuales.
El menú Servicios es la vista del usuario de una herramienta llamada OneFlow, que está diseñada para permitir la escalabilidad de las aplicaciones mediante el lanzamiento de nuevas máquinas virtuales basadas en diferentes parámetros, como la carga de los servicios en ejecución. Actualmente no está habilitado.
Máquinas Virtuales#
 El menú Máquinas virtuales enumera todas las máquinas virtuales asociadas con la cuenta o el grupo. Para cada VM se muestran los parámetros de capacidad y las interfaces de red.
El menú Máquinas virtuales enumera todas las máquinas virtuales asociadas con la cuenta o el grupo. Para cada VM se muestran los parámetros de capacidad y las interfaces de red.
Se puede acceder a las máquinas virtuales a través de sus interfaces de red cuando están configuradas y a través de la consola VNC proporcionada por la interfaz web:
Plantillas#
Se pueden lanzar nuevas instancias de máquinas virtuales de dos formas, utilizando plantillas previamente definidas en el sistema o tomando instantáneas de máquinas virtuales que ya están en ejecución.
Crear instancias desde una plantilla#
 Usando el botón más (+) en el menú de VMs es posible crear una nueva máquina virtual con la configuración definida en una plantilla.
Usando el botón más (+) en el menú de VMs es posible crear una nueva máquina virtual con la configuración definida en una plantilla.
Las plantillas previamente definidas en la interfaz de la nube se enumeran en el menú Sistema, mientras que las plantillas creadas a partir de máquinas virtuales en ejecución se enumeran en el Menú guardado.
Con ambas opciones para crear una nueva VM, después de seleccionar la plantilla de origen, puede establecer el nombre de la VM e iniciar la creación con el botón Crear.
Vista de usuario#
La interfaz web de OpenNebula (llamada Sunstone) proporciona vistas para diferentes roles de usuario en los sistemas de gestión de la nube. El usuario puede acceder a una vista extendida (vista de usuario) con la opción Cambiar vista en la configuración del perfil de usuario.

 The Dashboard gives a glimpse on how resources are used.
The Dashboard gives a glimpse on how resources are used.
Bajo el menú Virtual Resources se puede acceder a la lista de máquinas virtuales que realmente se ejecutan en la nube, a las Plantillas que definen los parámetros de las nuevas máquinas virtuales e Imágenes asociadas a las máquinas virtuales o datos relacionados como imágenes en CDROM de otros sistemas operativos.
The Marketplace es una herramienta que nos brinda acceso rápido a imágenes y dispositivos listos para ejecutar para probar una variedad de software y sistemas operativos, proporcionados por diferentes entidades editoras.
Finalmente, OneFlow es una herramienta avanzada para mejorar la escalabilidad de las aplicaciones mediante el lanzamiento de nuevas máquinas virtuales en función de diferentes parámetros, por ejemplo, la carga de los servicios en ejecución.
Crear Instantáneas#
Es posible tomar una instantánea de una máquina virtual y usarla como plantilla para nuevas máquinas virtuales si tiene permisos para ello. Para hacer esto, el primer paso es apagar la VM. Puede enviar un comando de apagado con el botón de encendido dentro del menú de la máquina virtual o usando el comando de apagado en el shell de la máquina virtual.

 Cuando la máquina virtual está apagada, el botón de guardar está habilitado y se puede realizar la copia de la imagen. Este procedimiento también crea una nueva plantilla en Plantillas guardadas.
Cuando la máquina virtual está apagada, el botón de guardar está habilitado y se puede realizar la copia de la imagen. Este procedimiento también crea una nueva plantilla en Plantillas guardadas.
El tiempo necesario para tomar la instantánea depende del tamaño de la imagen de la máquina virtual.
Gestión de Máquinas Virtuales#
- Acceso a OpenNebula
Al seleccionar una máquina virtual verá el siguiente menú:
- Acceso remoto a una MV mediante VNC

- Bloqueo/Desbloqueo de la MV
- Suspender/Parar la MV

- Apagar la MV
- Reiniciar la MV
Ended: OpenNebula
Ended: Infraestructura en la nube (IaaS)
Servicios ↵
NextCloud ↵
Introducción a NextCloud#

Nextcloud nace en 2016 como un fork de ownCloud. El motivo se sospecha que fueron ciertas diferencias culturales y de valores entre varios desarrolladores del proyecto, más próximos a la cultura del software libre, y otros miembros más centrados en el negocio en si, y no tanto en la comunidad.
Información
El proyecto está mantenido actualmente por Nextcloud GmbH junto con una gran comunicad de usuarios y desarrolladores que colaboran activamente en él. Además, como ocurre con otros tantos proyectos de software libre, en Github puede visualizarse su código fuente, y hacer un seguimiento de su desarrollo.
La visión de NextCloud es recuperar el control de tu información pero manteniendo a la vez todo el conjunto de funcionalidades que han popularizado otras plataformas y/o servicios SaaS privativos como Dropbox, Google Drive u Microsoft Office 365, por mencionar algunas de las más populares.
A diferencia de las plataformas SaaS centralizadas, lo que nos ofrece Nextcloud es directamente el software que nos permitirá construir nuestra propia plataforma, ya sea a nivel de usuarios individules, o también a nivel de empresas o instituciones que deseen optar por una solución que pueda ser controlada, gestionada y por ellos.
Cita
Nextcloud pretende ser un completo centro de ocio y trabajo. Para ello, ofrece multiples capacidades de almacenamiento, colaboración, chat, comunicaciones audio/vídeo, calendario, contactos, y un largo etcétera.
¿Qué es NextCloud?#
Nextcloud es un software de código abierto que nos permite alojar archivos en la Nube y, además permite visualizarlos directamente desde un sitio web o apps, compartirlos, etc.
Con él, cualquier usuario con una cuenta puede subir información y se sincronizará con los demás usuarios en cualquiera de sus dispositivos.
Cita
La diferencia más notable con respecto a OwnCloud es que NextCloud ofrece una moderna plataforma de colaboración de contenidos in situ con edición de documentos en tiempo real, videochat y trabajo en grupo en el móvil, el escritorio y la web.
¿Para que sirve NextCloud?#
Información
La función básica de NextCloud es la de sustituir a OwnCloud y mejorar la experiencia de usuario.
El sistema de almacenamiento en la nube NextCloud tiene funcionalidades mejoradas con respecto a OwnCloud:
Mayor seguridad: Nextcloud incluye opciones de cifrado avanzado y autenticación de dos factores para proteger su información y evitar el acceso no autorizado.
Mayor flexibilidad: Nextcloud tiene una mayor cantidad de integraciones con otras aplicaciones y servicios, lo que significa que puede acceder a sus archivos de manera más rápida y fácil.
Mejoras en la colaboración: Nextcloud incluye herramientas de colaboración mejoradas, como la opción de dejar comentarios en documentos y ver la actividad reciente de otros usuarios. Esto puede hacer que sea más fácil trabajar en proyectos en equipo y mantenerse al día con el progreso de los demás.
Mejoras en la productividad: Nextcloud incluye aplicaciones y complementos que pueden ayudar a mejorar la productividad, como un calendario compartido, un administrador de tareas y una aplicación de correo electrónico.
Código abierto: Nextcloud es una plataforma de código abierto, lo que significa que está respaldada por una comunidad de desarrolladores y usuarios que contribuyen constantemente a su mejora y actualización. Esto garantiza que estaremos utilizando una herramienta de vanguardia y siempre estará a la vanguardia de las últimas tendencias y tecnologías.
Para más información tiene a su disposición la guía oficial
Características de la cuenta#

¿Cómo se accede?#
Para acceder a Nextcloud, sigue estos pasos:
-
Acceso a la Plataforma: Abre tú navegador web e ingresa la URL de tu instancia de Nextcloud https://nextcloud.iter.es.

-
Iniciar Sesión: Introduce tus credenciales de inicio de sesión de ITER, generalmente consisten en un nombre de usuario y una contraseña.
-
Panel de Control: Una vez que hayas iniciado sesión, estarás en el panel de inicio de Nextcloud, desde donde podrás acceder y gestionar tus archivos y aplicaciones.
¿Qué politicas de seguridad hay?#
Nextcloud se esfuerza por garantizar la seguridad de tus datos. Algunas de las políticas de seguridad incluidas son:
Cifrado: Nextcloud permite cifrar tus archivos durante el almacenamiento y la transmisión para proteger tu privacidad.
Autenticación de Dos Factores (2FA): Puedes habilitar la autenticación de dos factores para una capa adicional de seguridad en el inicio de sesión.
Auditoría de Actividades: Nextcloud registra y mantiene un registro de actividades para rastrear los cambios en tus archivos y la actividad de los usuarios.
Control de Acceso: Configura políticas de acceso y permisos para garantizar que solo las personas autorizadas puedan acceder a los archivos y carpetas.
¿Qué sucede cuando elimino un archivo?#
Borrado de Archivos: Cuando borras un archivo, se envía a la papelera de reciclaje y se puede restaurar o eliminar permanentemente según tus necesidades.
Acceso desde Múltiples Ubicaciones: Puedes acceder y sincronizar tus archivos desde varias ubicaciones y dispositivos sin problemas.
Información
Normalmente si hay un acceso compartido y ambos acceden al mismo archivo el último en modificar ese archivo prevalecerá sobre los demás.
¿Qué cuota de espacio tengo disponible?#
Límite de Almacenamiento: Cada usuario tiene un límite predefinido de 20GB de espacio disponible para almacenar sus archivos
Visualización de la Cuota: Los usuarios pueden verificar cuánto espacio de almacenamiento han utilizado y cuánto les queda disponible en su cuenta. Esta información generalmente se muestra en el panel de control de Nextcloud.
Advertencias de Cuota Llena: Cuando un usuario se acerca al límite de su cuota de almacenamiento, Nextcloud puede mostrar advertencias para informar al usuario que está cerca de agotar su espacio asignado.
Características de la cuenta#
¿Qué tipos de cuentas hay disponibles?#
En el marco actual del ITER, se proporciona a cada integrante una cuenta de tipo usuario, la cual se ve limitada a una capacidad de almacenamiento de 20GB. Adicionalmente, se facilita una cuenta departamental por cada departamento, caracterizada por disponer de una cuota de almacenamiento superior en comparación con la cuenta de usuario.
La gestión de la cuenta departamental recae sobre una única persona designada dentro del departamento, la cual posee la responsabilidad de administrar el acceso y la distribución de los contenidos almacenados, garantizando así una adecuada coordinación y compartición de los recursos entre los miembros del departamento.
¿Cómo configurar más de una cuenta en el cliente de Nextcloud?#
Para tener disponibles ambas cuentas en el cliente de Nextcloud debes seguir los siguientes pasos descritos a continuación:
-
Haz clic con el botón izquierdo en el icono del sistema del cliente de Nextcloud y abre el dialogo principal. Ahora haz clic en el menú desplegable donde aparece el nombre de usuario. Deberías poder ver lo siguiente:
-
Haz clic sobre agregar cuenta:
-
Deberías ver lo siguiente. Aquí deberás pulsar sobre "Log in" he introducir la URL. En nuestro caso la URL sería https://nextcloud.iter.es:
-
Ahora te aparecera la siguiente pantalla y te redirigirá al navegador para que allí inicies sesión con las credenciales del usuario o del departamento según corresponda.
-
Por último, elige la carpeta con la que el cliente de NextCloud debe sincronizar el contenido de tu cuenta de NextCloud.
-
Si todo ha ido bien deberías ver el siguiente icono en tus iconos del sistema:

Interfaz web de NextCloud#
La interfaz web de usuario de NextCloud viene con un diseño renovado para adaptarse mejor a las necesidades de cada empresa y permite así establecer un fondo y logo corporativo.
Información
Desde aquí podrás acceder a tus archivos, así como: crear, previsualizar, editar, eliminar, compartir y recompartir archivos.
Nota
Tu administrador de NextCloud tiene la opción de desactivar algunas funciones. Si ves que alguna de las siguientes falta en tu sistema, pregunte directamente al administrador de tu NextCloud.
Iniciando sesión desde la interfaz web#
Deberemos iniciar sesión con nuestras credenciales de ITER en la siguiente url: https://nextcloud.iter.es
Información
Actualmente NextCloud usa LDAP para la autenticación de usuarios por lo que únicamente necesitaremos iniciar sesión para estar registrados.
Una vez hemos iniciado sesión nos encontraremos con la siguiente pantalla:
Información
Por defecto, la interfaz web de NextCloud se abre en el panel de control. Aquí podrás obtener las notificaciónes y los cambios más recientes.
Navegando por la interfaz de usuario principal#
Situándonos en "archivos" podemos añadir, eliminar y compartir archivos, y el administrador del servidor puede cambiar los privilegios de acceso.
La interfaz de usuario de Nextcloud contiene los siguientes campos y funciones:
- Menú de selección de Apps (1): Se encuentra en la esquina superior izquierda, y en él encontrará las aplicaciones que tiene disponibles en su instancia de Nextcloud. Al hacer clic en el icono de una aplicación se le redirigirá a ella.
- Campo de información de la aplicación (2): Situado en la barra lateral izquierda, ofrece filtros y tareas asociadas con la aplicación actual. Por ejemplo, en la aplicación Archivos aparecen una serie de filtros para encontrar archivos fácilmente, como por ejemplo archivos que han compartido con usted, y archivos que usted ha compartido. Cada aplicación tendrá elementos distintos.
- Vista de la aplicación (3): El campo central y principal de la interfaz de usuario de Nextcloud. Este campo muestra el contenido o características de la aplicación seleccionada.
- Barra de navegación (4): Situada sobre la ventana principal (la vista de la aplicación), esta barra muestra la ruta actual, que le permite moverse rápidamente a carpetas superiores, hasta el nivel raíz (la carpeta principal).
- Botón nuevo (5): Situado en la barra de navegación, el botón Nuevo permite crear nuevos archivos o carpetas, y subir archivos.
Información
También es posible arrastrar y soltar archivos desde su gestor de archivos a la vista de la aplicación Archivos para subirlos a su instancia (si su navegador soporte «drag and drop»)
- Campo de búsqueda (6): Haga clic en la lupa de la esquina superior derecha para buscar entre sus archivos
- Menú de Contactos (7): Le ofrece un resumen de sus contactos y usuarios en su servidor. En función de los detalles y aplicaciones disponibles, es posible empezar una videoconferencia con ellos o enviarles un correo electrónico.
- Botón de vista en cuadrícula (8): Este botón está formado por cuatro pequeños cuadrados, y alterna la vista en cuadrícula para carpetas y archivos.
- Menú de Ajustes (9): Para abrir el menú desplegable de Ajustes, haga clic en su foto de perfil, situada a la izquierda del campo de Búsqueda. Su página de Ajustes le ofrece las siguientes características y configuraciones:
- Enlaces para la descarga de aplicaciones de escritorio y móviles
- Uso del servidor y espacio disponible.
- Gestión de contraseñas
- Configuración de su nombre, correo electrónico y foto de perfil
- Gestionar los navegadores y dispositivos conectados
- Membresías en grupos
- Configuración del idioma de la interfaz
- Gestionar notificaciones
- Identificador de nube federada y botones para compartir en redes sociales
- Gestor de certificados SSL/TLS para almacenamiento externo
- Configuración de verificación en dos pasos
- Información sobre la versión de Nextcloud
Para más información tiene a su disposición la guía oficial
Compartiendo archivos en NextCloud#
Los usuarios de Nextcloud pueden compartir archivos y carpetas. Los objetivos posibles son:
- Enlaces públicos
- Usuarios
- Grupos
- Círculos
- Conversaciones
- Usuarios o grupos en servidores Nextcloud federados
Al hacer clic en el icono de compartir en cualquier archivo o carpeta, se abre la vista de detalles a la derecha, donde la pestaña Compartir tiene el foco.
¿Cómo se crean Espacios Compartidos?#
Para crear espacios compartidos en Nextcloud y compartirlos con otros usuarios, sigue estos pasos:
-
Selecciona un Archivo o Carpeta: En tu panel de control, selecciona un archivo o carpeta que desees compartir.

-
Opciones de Compartir: Haz clic en la opción "Compartir" y elige con quién deseas compartir el archivo o carpeta. Puedes compartirlo con usuarios específicos o generar un enlace de acceso público.
-
Configura los Permisos: Define los permisos de acceso, como "Lectura" o "Edición", y establece una fecha de vencimiento si es necesario.
-
Envía la Invitación: Notifica a los usuarios con quienes compartes el archivo mediante correos electrónicos o compartiendo el enlace generado.
Formas de compartir los archivos#
Enlaces públicos compartidos#
Puedes compartir archivos y carpetas a través de enlaces públicos.
Se creará un token aleatorio de 15 dígitos. El enlace tendrá el aspecto de https://cloud.example.com/s/yxcFKRWBJqYYzp4.
Existen varias opciones para compartir carpetas públicas:
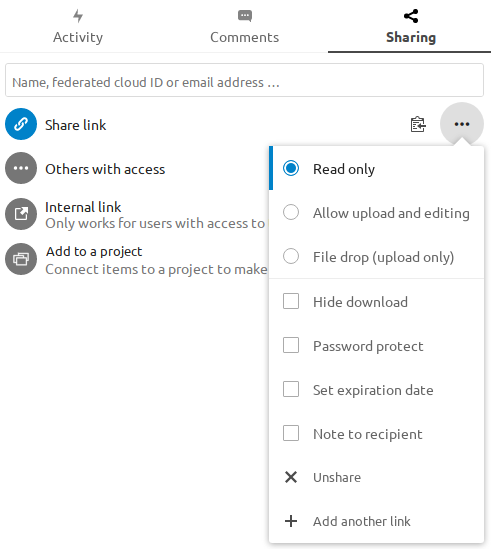
- Sólo lectura para permitir la visualización y descarga
- Permitir subir y editar
- Con Subir archivos, el compartidor sólo puede subir archivos a una carpeta sin ver los archivos que ya están en esa carpeta.
- Ocultar descarga oculta los botones de descarga y las opciones predeterminadas del botón derecho del navegador para dificultar la descarga para el sharee
- Proteger con contraseña
- Establecer fecha de caducidad desactivará automáticamente el recurso compartido
- Nota para el destinatario
- Descompartir para revertir la acción
- Añadir otro enlace para crear varios enlaces públicos con diferentes derechos
Nota
La protección por contraseña y la caducidad de los archivos no se propagan mediante el uso compartido de archivos federados en las versiones actuales de Nextcloud. Esto se ha ajustado en Nextcloud 22.
Uso compartido interno con usuarios y grupos#
Al compartir con usuarios, grupos, o círculos, los derechos para los archivos o el contenido de las carpetas son ajustables:
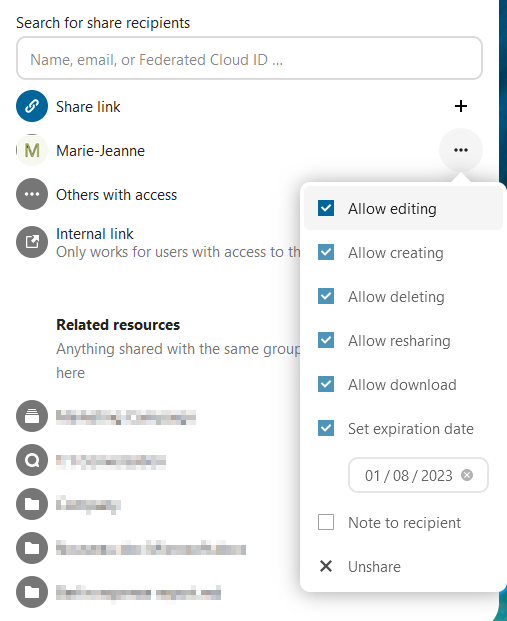
Como compartidor, puedes configurar si quieres aceptar automáticamente todas las comparticiones entrantes y que se añadan a tu carpeta raíz, o si quieres que se te pregunte cada vez si quieres aceptar o rechazar la compartición.
Para ajustar la aceptación, ve a Ajustes > Personal > Compartir:

Otros con acceso#
Para saber si un archivo o carpeta es accesible a otros a través de la compartición de un nivel jerárquico de carpeta superior, haz clic en Otros con acceso en la pestaña de compartición:
La lista muestra todos los usuarios, grupos, etc. a los que se ha dado acceso al objeto actual mediante el uso compartido de una carpeta superior en la jerarquía:
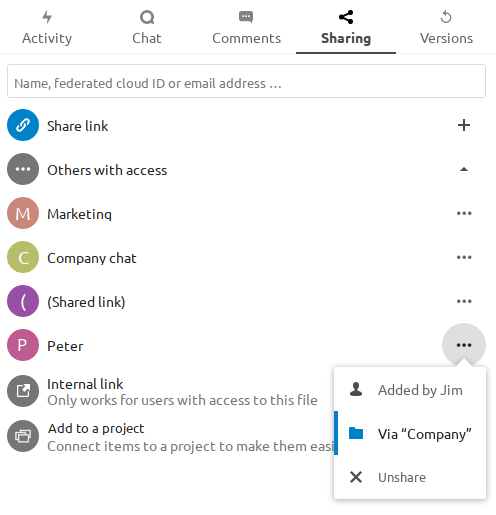
Haz clic en los tres puntos para:
- ver quién inició el intercambio
- ver dónde se inició la compartición (haz clic para navegar hasta la carpeta, siempre que tengas acceso a ella)
- anular la compartición inicial (sólo accesible para el propietario de la compartición)
Nota
Esta información sólo es visible para el propietario de un archivo/carpeta o para los usuarios con derechos para volver a compartir.
Para más información tiene a su disposición la guía oficial
Control de versiones de NextCloud#
Nextcloud admite un sencillo sistema de control de versiones para los archivos. El control de versiones crea copias de seguridad de los archivos a las que se puede acceder a través de la pestaña "Versiones" de la barra lateral "Detalles".
Esta pestaña contiene el historial del archivo, en el que se puede hacer retroceder un archivo a cualquier versión anterior. Los cambios realizados en intervalos superiores a dos minutos se guardan en data/[usuario]/files_versions.
Para restaurar una versión concreta de un archivo, haz clic en la flecha circular de la derecha. Haz clic en la marca de tiempo para descargarla.
La aplicación de versionado expira las versiones antiguas automáticamente para asegurarse de que el usuario no se queda sin espacio. Este patrón se utiliza para eliminar versiones antiguas:
- Para el primer segundo mantenemos una versión
- Durante los primeros 10 segundos Nextcloud mantiene una versión cada 2 segundos
- Durante el primer minuto Nextcloud guarda una versión cada 10 segundos
- Durante la primera hora, Nextcloud conserva una versión cada minuto.
- Durante las primeras 24 horas Nextcloud guarda una versión cada hora
- Durante los primeros 30 días Nextcloud guarda una versión cada día
- Después de los primeros 30 días, Nextcloud conserva una versión cada semana.
Las versiones se ajustan siguiendo este patrón cada vez que se crea una nueva versión.
La aplicación de versiones nunca utiliza más del 50% del espacio libre disponible del usuario. Si las versiones almacenadas superan este límite, Nextcloud borra las versiones más antiguas hasta que vuelve a alcanzar el límite de espacio en disco.
Para más información tiene a su disposición la guía oficial
Aplicación de escritorio en NextCloud#
Con esta herramienta pueden mantenerse sincronizados las carpetas y los archivos de su cuenta de NextCloud con una carpeta en el equipo local del usuario, de modo similar a como funcionan otras herramientas de software (por ejemplo Dropbox).
Información
La sincronización continua hacia y desde el servidor NextCloud proporciona facilidad de uso combinada con un amplio control de acceso.
Instalación de la aplicación de escritorio#
El cliente de Nextcloud es multiplataforma, puede ser instalado fácilmente en sistemas operativos Linux, Windows y macOS.
Instalación en Linux#
En sistemas operativos Linux el cliente de Nextcloud puede instalarse ejecutando los siguientes comandos en una terminal:
$ sudo add-apt-repository ppa:nextcloud-devs/client
$ sudo apt update
$ sudo apt install nextcloud-client
También es posible descargar el instalador del programa para Linux desde la página de descarga del cliente de Nextcloud: https://nextcloud.com/install/#install-clients
Información
Una vez que se instala, es necesario configurar la herramienta en la primera ejecución.
Instalación en Mac OS X y Windows#
La instalación en Mac OS X y Windows es la misma que para cualquier aplicación de software:
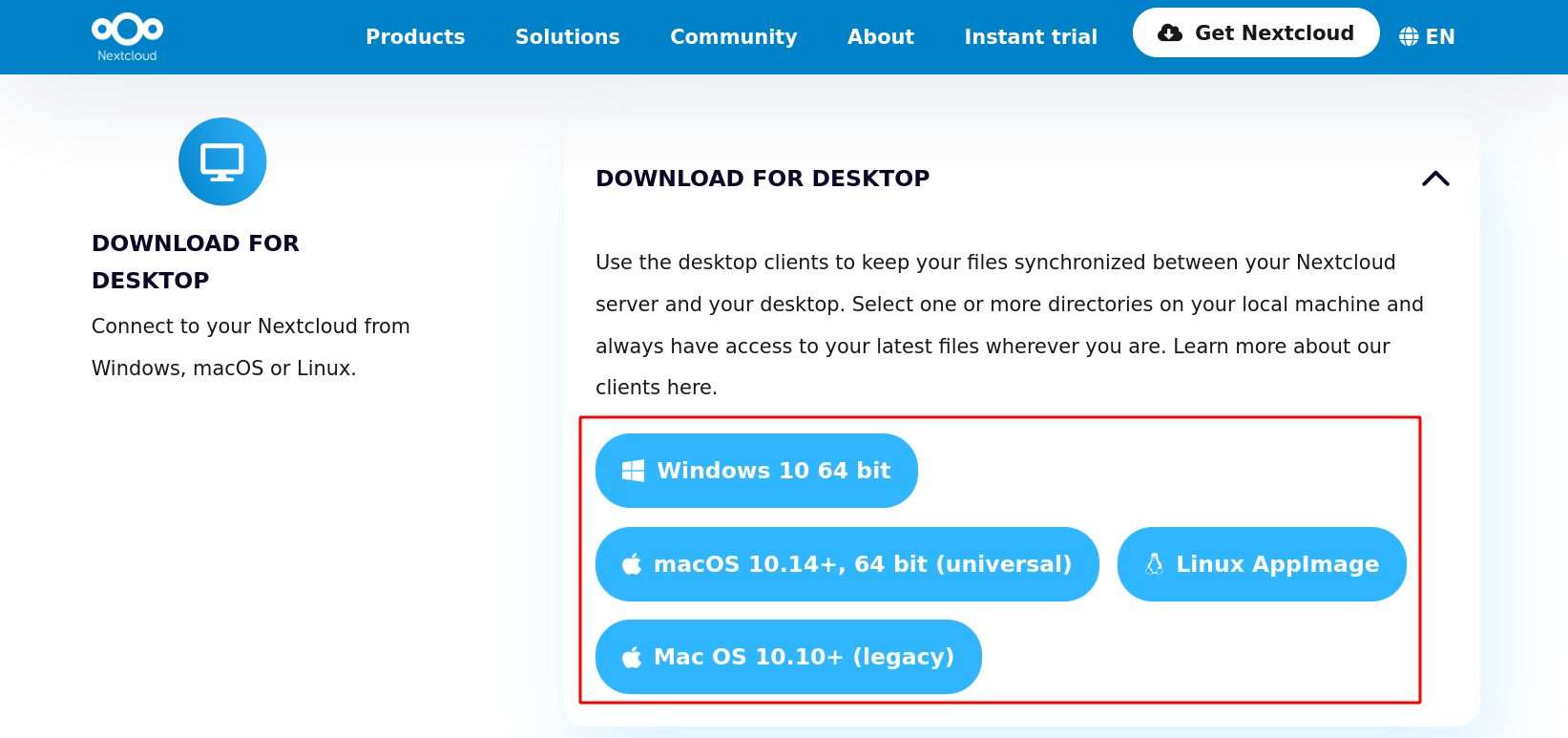
- Descargue el instalador en la siguiente URL
- Haga doble clic en él para iniciar la instalación y siga el asistente de instalación.
Uso de la aplicación de escritorio#
La aplicación de escritorio NextCloud permanece en segundo plano y es visible como un icono en la bandeja del sistema (Windows, KDE), en la barra de menús (macOS) o en el área de notificación (Linux).
Iconos de aplicación utilizados#

El indicador de estado utiliza iconos para indicar el estado actual de su sincronización. El círculo verde con la marca de verificación blanca te indica que tu sincronización está en curso y que estás conectado a tu servidor Nextcloud.

El icono azul con los semicírculos blancos significa que la sincronización está en curso.

El icono amarillo con las líneas paralelas le indica que la sincronización se ha pausado. (Lo más probable es que por usted).

El icono gris con tres puntos blancos significa que tu aplicación de escritorio ha perdido la conexión con tu servidor de NextCloud.

Cuando veas un círculo amarillo con el signo "!", ése es el icono informativo, así que debes hacer clic en él para ver qué tiene que decirte.

El círculo rojo con la "x" blanca indica un error de configuración, como un inicio de sesión o una URL de servidor incorrectos.
Configurar una cuenta#
El asistente de instalación te guía paso a paso a través de las opciones de configuración y la configuración de la cuenta. En primer lugar, debes pulsar el botón "logueate em tú NextCloud".
Ahora deberás introducir la URL del servidor de NextCloud.
En nuestro caso la URL sería https://nextcloud.iter.es o https://192.168.53.13
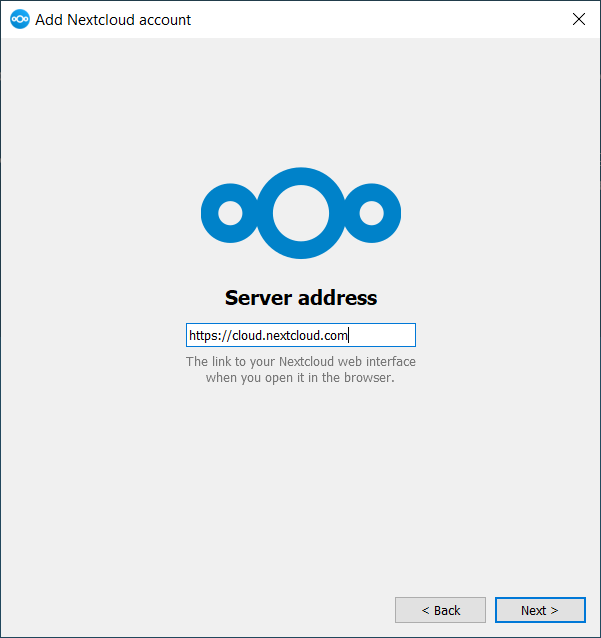
Ahora te aparecera la siguiente pantalla y te redirigirá al navegador para que allí inicies sesión con las mismas credenciales que utilizaría para iniciar sesión a través de la interfaz web.
Por último, elige la carpeta con la que el cliente de NextCloud debe sincronizar el contenido de tu cuenta de NextCloud.
Tras pulsar "Conectar", NextCloud Client comenzará con el proceso de sincronización.
Si todo ha ido bien deberías ver el siguiente icono en tus iconos del sistema:
Para más información tiene a su disposición la guía oficial
Migración desde el cliente de escritorio de OwnCloud a NextCloud#
Actualmente si seguís usando la aplicación de escritorio de OwnCloud os encontraréis con el siguiente mensaje: !La versión del servidor de no es compatible!. Continúa bajo tu responsabilidad.
No os preocupéis, podéis seguir trabajando sin problemas. Pero es recomendable hacer la migración hacía la aplicación de escritorio de NextCloud.
Pasos a seguir#
1. Detener el cliente owncloud#
La forma de detener el cliente ownCloud desde la aplicación de escritorio depende de la plataforma que esté utilizando.
Windows#
Haga "click derecho" en el icono de ownCloud en la barra de tareas y seleccione "Cerrar" o "Salir" para detener el cliente.
MacOS#
Haga clic en el icono ownCloud en la barra de menús superior y seleccione "Salir" para detener el cliente.
Linux#
Haga clic en el icono ownCloud en la barra de tareas y seleccione "Salir" o "Cerrar" para detener el cliente.
2. Eliminar el cliente owncloud#
La forma de eliminar el cliente de escritorio de ownCloud depende de la plataforma que esté utilizando.
Windows#
Ir a "Agregar o quitar programas" en el Panel de control y buscar ownCloud, luego seleccione "Desinstalar" para eliminar el cliente.
MacOS#
Arrastrar el icono de ownCloud desde la carpeta Aplicaciones a la papelera, luego vacíe la papelera para eliminar el cliente.
Linux#
Utilice el administrador de paquetes de su distribución para buscar y eliminar ownCloud.
Por ejemplo, si está utilizando Ubuntu, puede abrir el terminal y ejecutar el siguiente comando:
3. Instalar el cliente nextcloud#
Los pasos de indican en la siguiente URL:
4. Inicie el cliente nextcloud#
Inicielo una única vez y ciérrelo justo cuando el asistente le pregunte por el servidor, etc.
Debe llegar hasta la siguiente ventana:
5. Mueve tú fichero owncloud.cfg#
Copie su fichero oculto owncloud.cfg localizado en el directorio principal de OwnCloud al directorio principal de NextCloud como nextcloud.cfg creado por el cliente en el paso 3.
Dependiendo de la plataforma la ruta por defecto será diferente.
Windows#
En Microsoft Windows: %LOCALAPPDATA%\ownCloud\owncloud.cfg
MacOS#
En MAC OS X: $HOME/Library/Application Support/ownCloud
Linux#
En distribuciones Linux: $HOME/.local/share/data/ownCloud/owncloud.cfg o $HOME/.config/owncloud/owncloud.cfg
6. Inicie el cliente nextcloud#
Te pedirá la contraseña y después continuará donde terminó tu cliente owncloud.
Información
No se deberían transferir datos nuevos una vez hecho el procedimiento.
Copias de seguridad en Nextcloud#
Nextcloud es una excelente solución para el almacenamiento y sincronización de archivos en la nube, pero no está diseñado específicamente para ser utilizado como una solución de respaldo.
Peligro
Se recomienda encarecidamente no usar Nextcloud para hacer copias de seguridad.
Razones#
Existen varias razones por las cuales no se recomienda utilizar Nextcloud como backup:
No es una solución de backup completa#
No es una solución de backup completa: Nextcloud es una solución de sincronización y almacenamiento de archivos, no una solución de backup completa. Una solución de backup completa debe incluir características como programación de copias de seguridad automáticas, verificación de integridad de datos y posibilidad de restaurar archivos a una fecha específica.
No se pueden hacer copias de seguridad incrementales#
No se pueden hacer copias de seguridad incrementales: En Nextcloud, cada vez que se guarda un archivo, se sobrescribe la versión anterior del archivo. Esto significa que no se pueden hacer copias de seguridad incrementales, lo que es esencial para una solución de backup efectiva.
Riesgo de corrupción de datos#
Riesgo de corrupción de datos: Si un archivo se corrompe o se elimina accidentalmente en Nextcloud, se eliminará en todas las instancias de la nube. Esto significa que si se produce un error en Nextcloud, se puede perder toda la información.
Limitaciones de almacenamiento#
Limitaciones de almacenamiento: Nextcloud puede estar limitado en cuanto a la cantidad de almacenamiento que se puede utilizar para el almacenamiento de archivos. Si se utiliza para hacer copias de seguridad, puede ser difícil o costoso ampliar el almacenamiento necesario.
Información
Es importante asegurarse de que los datos estén bien respaldados para evitar la pérdida de información valiosa en caso de una falla en el sistema o una eliminación accidental.
Información
Asegúrese de elegir una solución de backup que se adapte a sus necesidades y que cuente con características como programación de copias de seguridad automáticas, verificación de integridad de datos y posibilidad de restaurar archivos a una fecha específica. Además, siempre es recomendable realizar pruebas regulares de restauración para garantizar que los datos se puedan recuperar correctamente en caso de una emergencia.
Por estas razones, se recomienda utilizar una solución de copia de seguridad dedicada para proteger adecuadamente los datos importantes.
Ended: NextCloud
OnDemand ↵
Introducción a Open OnDemand#
Open OnDemand es una plataforma revolucionaria basada en web diseñada para proporcionar a los usuarios un acceso fácil y seguro a recursos de cómputo de alto rendimiento (HPC). Esta interfaz amigable simplifica el proceso de usar sistemas HPC complejos al permitir a los usuarios realizar una amplia gama de tareas a través de un navegador web estándar, eliminando la necesidad de interacciones tradicionales de línea de comandos. Open OnDemand democratiza el acceso a recursos informáticos potentes, haciéndolos accesibles para una gama más amplia de disciplinas y niveles de experiencia.
Características Clave#
Open OnDemand ofrece una variedad de características diseñadas para mejorar la experiencia del usuario y mejorar el acceso a los recursos TeideHPC:
- Acceso Basado en Web: Los usuarios pueden acceder a los recursos TeideHPC desde cualquier navegador web estándar, sin necesidad de VPNs o software cliente especializado.
- Aplicaciones Interactivas: Open OnDemand permite a los usuarios lanzar aplicaciones GUI interactivas (como Jupyter Notebooks, RStudio y Matlab) directamente en su navegador, facilitando la realización de cálculos y análisis complejos.
- Gestión de Archivos: Un navegador de archivos integrado permite a los usuarios cargar, descargar, editar y gestionar fácilmente sus archivos y directorios en el sistema TeideHPC.
- Gestión de Trabajos: Los usuarios pueden enviar, monitorear y gestionar trabajos por lotes directamente desde la interfaz web, con soporte para scripts de trabajo y una variedad de sistemas de envío de trabajos.
- Acceso a Shell: Para los usuarios avanzados que prefieren interfaces de línea de comandos, Open OnDemand proporciona acceso integrado a terminales shell, permitiendo la interacción directa con el entorno Linux subyacente del sistema TeideHPC.
Ventajas de Open OnDemand#
La principal ventaja de Open OnDemand es su capacidad para hacer los recursos TeideHPC más accesibles y fáciles de usar. Esta accesibilidad fomenta la innovación y colaboración en una amplia gama de disciplinas científicas, de ingeniería y análisis de datos. Otras ventajas incluyen:
- Curva de Aprendizaje Reducida: Al proporcionar una interfaz gráfica para tareas tradicionalmente realizadas a través de la línea de comandos, Open OnDemand reduce significativamente la barrera de entrada para nuevos usuarios de TeideHPC.
- Productividad Mejorada: El flujo de trabajo simplificado que ofrece Open OnDemand permite a los investigadores concentrarse más en su investigación y menos en dominar las complejidades de los sistemas HPC.
- Colaboración y Compartición: Open OnDemand facilita la colaboración entre investigadores al hacer más fácil compartir aplicaciones, datos y resultados.
Casos de Uso#
Open OnDemand es versátil y puede soportar una amplia gama de casos de uso, incluyendo, pero no limitado a:
- Análisis y Visualización de Datos: Los investigadores pueden realizar análisis de datos utilizando sus herramientas preferidas y visualizar resultados directamente en su navegador web.
- Simulación y Modelado: Ingenieros y científicos pueden ejecutar simulaciones y modelos en recursos computacionales potentes, ajustando parámetros y analizando resultados en tiempo real.
- Fines Educativos: Los educadores pueden usar Open OnDemand para proporcionar a los estudiantes experiencia práctica con recursos HPC, habilitando aprendizaje práctico en cursos que requieren un poder computacional significativo.
Cómo Comenzar#
Para comenzar con Open OnDemand, los usuarios típicamente necesitan:
- Tener una cuenta en TeideHPC desde la cual tendrán acceso a Open OnDemand.
- Navegar al portal de Open OnDemand en https://ondemand.hpc.iter.es/ usando un navegador web.
- Autenticarse usando sus credenciales de cuenta TeideHPC.
A partir de ahí, los usuarios pueden explorar las aplicaciones disponibles, gestionar archivos, enviar trabajos y más, todo a través de una interfaz web intuitiva.
Trabajando con Archivos en OnDemand#
Antes de trabajar en el cluster, es importante entender dónde deben almacenarse los diferentes tipos de archivos en la jerarquía de carpetas. Por lo tanto, recomendamos encarecidamente revisar nuestra página de almacenamiento de Datos para obtener esta información.
Acceso a la página de Archivos en OnDemand#
- Conéctate a OnDemand en https://ondemand.hpc.iter.es/ con tus credenciales.
- Haz clic en Archivos.
- Selecciona Directorio principal.
Deberías ver lo siguiente:
Crear una carpeta#
- Conéctate a OnDemand en https://ondemand.hpc.iter.es/ con tus credenciales.
- Haz clic en Archivos.
- Selecciona Directorio principal
- Haz clic en Nuevo Directorio.
- Ingresa el nombre del directorio.
- Haz clic en OK.
¡El directorio ha sido creado!. Puedes navegar a él seleccionándolo en la interfaz de archivos, y ahora puedes añadir archivos allí.
Subir un archivo#
- Conéctate a OnDemand en https://ondemand.hpc.iter.es/ con tus credenciales.
- Haz clic en Archivos.
- Selecciona Directorio principal
- Haz clic en Subir.
- Selecciona Examinar archivos para subir un archivo.
- Navega al archivo que te gustaría subir. Ten en cuenta que puedes seleccionar varios.
- Haz clic en Subir archivo.
Tu archivo ha sido subido al directorio que especificaste en Adroit. Puedes ver el archivo haciendo clic en su nombre de archivo en la interfaz de Archivos.
NOTA:
Cuando subes archivos a través del portal OnDemand, cada subida está limitada a un tamaño de 2 GB. Si necesitas subir archivos más grandes, recomendamos usar comandos de Linux, como se describe en nuestra página de transferencia de datos. Puedes introducir estos comandos de Linux dentro del Terminal, el cual puedes abrir como se describe en nuestra sección de ejecutar un terminal desde OnDemand más adelante en esta página. Contacta a support@hpc.iter.es si necesitas ayuda con esto.
Crear un archivo#
- Conéctate a OnDemand en https://ondemand.hpc.iter.es/ con tus credenciales.
- Haz clic en Archivos.
- Selecciona Directorio principal
- Haz clic en Nuevo Archivo.
- Ingresa el nuevo nombre del archivo.
- Haz clic en OK.
¡Tu archivo ha sido creado!
Editar un archivo#
- Conéctate a OnDemand en https://ondemand.hpc.iter.es/ con tus credenciales.
- Haz clic en Archivos.
- Selecciona Directorio principal
- Navega a tu archivo.
- Selecciona la opción del menú con 3 puntos verticales y una flecha hacia abajo al lado de tu archivo.
- Selecciona Editar del menú desplegable que aparece.
Ahora estás en la interfaz de edición para tu archivo. Rellénalo con cualquier contenido que necesites. Una vez que hayas terminado, haz clic en Guardar en la esquina superior izquierda de la interfaz del Editor.
Renombrar un archivo#
- Conéctate a OnDemand en https://ondemand.hpc.iter.es/ con tus credenciales.
- Haz clic en Archivos.
- Selecciona Directorio principal
- Navega a tu archivo.
- Selecciona la opción del menú con 3 puntos verticales y una flecha hacia abajo al lado de tu archivo.
- Selecciona Renombrar del menú desplegable que aparece.
- Ingresa tu nuevo nombre de archivo.
- Haz clic en OK.
¡Tu archivo ha sido renombrado!
Copiar/Mover un archivo#
- Conéctate a OnDemand en https://ondemand.hpc.iter.es/ con tus credenciales.
- Haz clic en Archivos.
- Selecciona Directorio principal
- Navega a tu archivo.
- Selecciona la casilla a la izquierda del(los) archivo(s) que te gustaría copiar/mover.
- Haz clic en el botón Copiar/Mover en la parte superior derecha de la interfaz de Archivos.
- Navega al directorio al que te gustaría copiar/mover tu(s) archivo(s).
- Haz clic en el botón Copiar o Mover en el diálogo en la parte izquierda de tu pantalla dependiendo de la operación que desees realizar.
¡Tu(s) archivo(s) han sido copiados/movidos!
Eliminar un archivo#
- Conéctate a OnDemand en https://ondemand.hpc.iter.es/ con tus credenciales.
- Haz clic en Archivos.
- Selecciona Directorio principal
- Navega a tu archivo.
- Selecciona la opción del menú con 3 puntos verticales y una flecha hacia abajo al lado de tu archivo.
- Selecciona Eliminar del menú desplegable que aparece. O:
- Selecciona la casilla a la izquierda del(los) archivo(s) que te gustaría eliminar.
- Haz clic en Eliminar en la esquina superior derecha de la interfaz de Archivos.
¡Tu(s) archivo(s) han sido eliminados!
Ejecución de trabajos en OnDemand#
Para ejecutar trabajos utilizando la interfaz OnDemand, debe crear un script slurm para su código. Para obtener más información sobre cómo enviar trabajos a los clústeres, le recomendamos que consulte nuestra Guía de mi primer trabajo con Slurm.
Acceder a la Pestaña de Trabajos#
Una vez que hayas iniciado sesión en OnDemand en https://ondemand.hpc.iter.es/, sigue estos pasos para acceder a la pestaña de trabajos:
- En la barra de navegación superior, encuentra y haz clic en el menú "Trabajos".
- Verás varias opciones, incluyendo "Trabajos activos", "Trabajos completados", y "Enviar trabajo". Selecciona la opción que desees para proceder.
Enviar un Nuevo Trabajo#
Para enviar un nuevo trabajo a través de la interfaz de OOD:
- Dentro de la pestaña de "Trabajos", selecciona "Enviar trabajo".
- Serás dirigido a una página donde puedes seleccionar la aplicación o el entorno de ejecución para tu trabajo. Elige la que se ajuste a tus necesidades.
- Completa el formulario con los detalles de tu trabajo, incluyendo recursos requeridos como número de núcleos, memoria y tiempo de ejecución.
- Opcional: Adjunta archivos o especifica comandos de ejecución según sea necesario.
- Haz clic en "Enviar" para encolar tu trabajo. Recibirás una confirmación con el ID de tu trabajo.
Monitorear y Gestionar Trabajos Activos#
Para ver y gestionar trabajos que has enviado:
- Ve a "Trabajos activos" desde la pestaña de "Trabajos".
- Aquí, puedes ver una lista de tus trabajos en ejecución o en cola, junto con su estado actual.
- Para acciones específicas como cancelar un trabajo, selecciona el trabajo deseado y utiliza las opciones disponibles.
Deberías ver lo siguiente:
Además puedes consultar todo los detalles de los trabajos desplegándolo con la pestaña de la izquierda. Podrás ver información como el id del trabajo, el nº de nodos usados, el estado, ...:
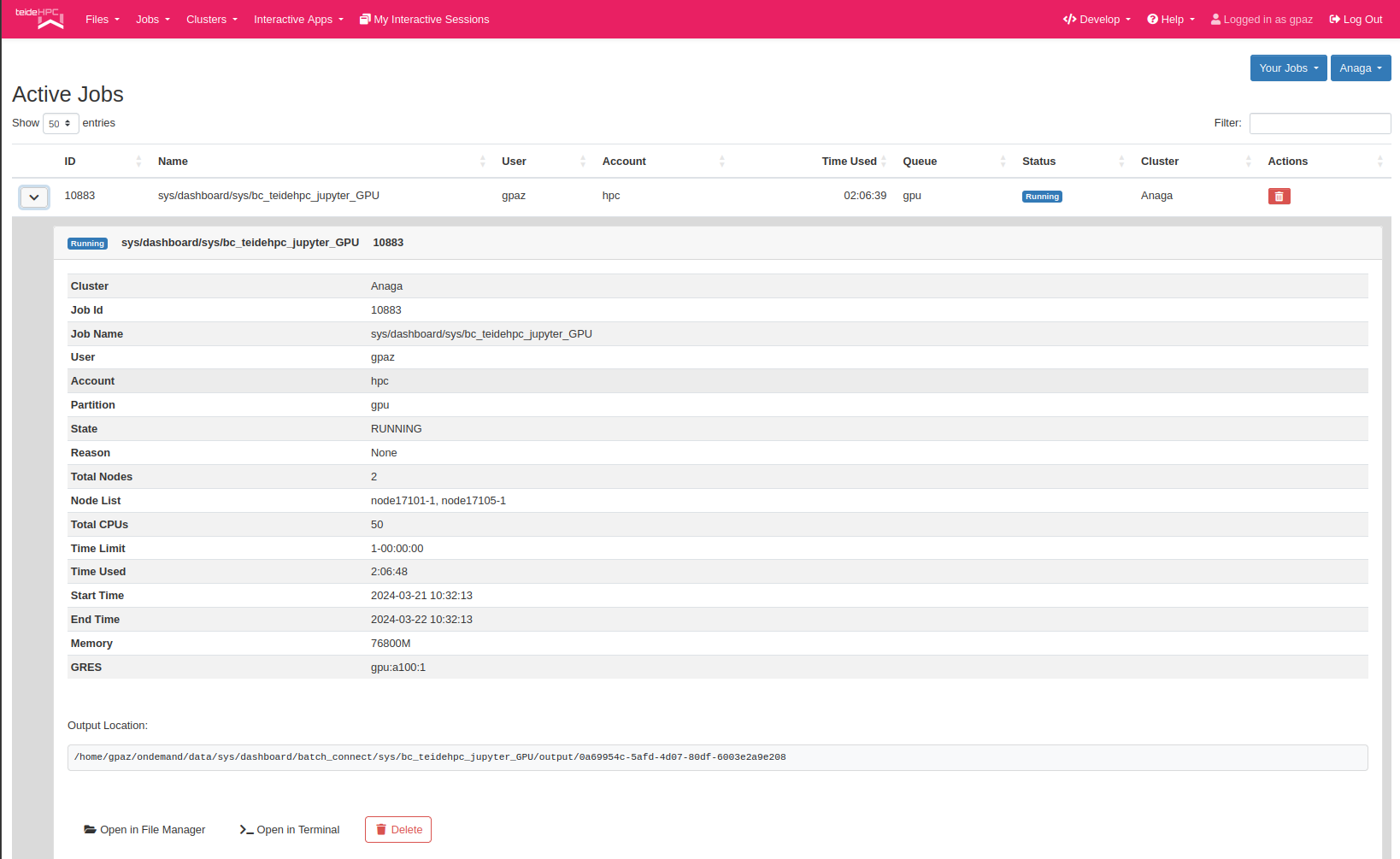
Consultar Trabajos Completados#
Para revisar trabajos que han finalizado:
- Selecciona "Trabajos completados" desde la pestaña de "Trabajos".
- Podrás ver una lista de trabajos con información sobre su ejecución y resultados.
- Utiliza esta sección para descargar resultados o analizar el rendimiento de tus trabajos.
Clústeres en TeideHPC#
En TeideHPC disponemos de dos clústeres: el clúster TeideHPC y el clúster Anaga.
La pestaña "Clusters" en OnDemand ofrece a los usuarios una interfaz gráfica para interactuar con los recursos de los clusters de supercomputación disponibles. A través de esta interfaz puedes acceder a terminales de los nodos de login de cada clúster.
Cómo Acceder a la Pestaña "Clusters"#
- Conéctate a OnDemand en https://ondemand.hpc.iter.es/ usando un navegador web.
- En la barra de navegación principal, encuentra y haz clic en la pestaña "Clusters".
- Verás una lista de los clusters disponibles a los cuales tienes acceso.
Al acceder deberías ver lo siguiente:
Aplicaciones Interactivas en OnDemand#
Acceso a las Aplicaciones Interactivas#
Para comenzar a usar las aplicaciones interactivas:
- Conéctate a OnDemand en https://ondemand.hpc.iter.es/ con tus credenciales.
- Dirígete a la pestaña "Interactive Apps" en la barra de navegación principal.
- Aquí encontrarás un listado de las aplicaciones disponibles. Selecciona la aplicación deseada: Code Server, JupyterLab, o RStudio, y elige entre la versión para CPU o para GPU según tus necesidades.
Aplicaciones Disponibles#
Code Server#
Code Server proporciona una versión de Visual Studio Code que se ejecuta en el servidor y es accesible a través del navegador. Ideal para desarrollo de software y edición de código.
- Para CPU/GPU: Selecciona la versión que necesites según el tipo de procesamiento requerido para tu proyecto.
- Configuración: Especifica los recursos necesarios (como número de cores, memoria y tiempo de ejecución). Para la versión GPU, asegúrate de seleccionar también el tipo de GPU deseado.
- Uso: Una vez lanzada, la aplicación abrirá Visual Studio Code en tu navegador, permitiéndote trabajar con tus archivos y proyectos almacenados en el servidor.
La aplicación te pedirá una contraseña para poder acceder:
Una vez dentro tendrás el editor de código referencia del marco actual:
JupyterLab#
JupyterLab ofrece un entorno interactivo de ciencia de datos que soporta lenguajes de programación como Python, R, y Julia.
- Para CPU/GPU: Elige según las demandas computacionales de tus notebooks de Jupyter.
- Configuración: Indica los recursos computacionales necesarios. Para la versión GPU, selecciona el tipo de GPU que prefieras.
- Uso: Al lanzar JupyterLab, se abrirá una nueva ventana en tu navegador para trabajar con notebooks, código, y datos.
Una vez dentro verás lo siguiente:
RStudio#
RStudio brinda un entorno de desarrollo integrado para R, facilitando la programación, visualización de datos, y más.
- Para CPU/GPU: Dependiendo del procesamiento necesario para tus análisis de datos, elige la versión adecuada.
- Configuración: Asigna los recursos que requieres, incluyendo el tipo de GPU si optas por esa versión.
- Uso: RStudio se abrirá en el navegador, proporcionando acceso a las herramientas de desarrollo de R en un entorno familiar.
Una vez dentro verás lo siguiente:
Consejos Generales#
- Guarda tu Trabajo: Asegúrate de guardar tus archivos y proyectos regularmente para no perder progreso.
- Gestiona tus Recursos: Cierra las aplicaciones interactivas cuando no las estés utilizando para liberar recursos en el cluster.
- Consulta la Documentación: Cada aplicación tiene características y configuraciones específicas. Consulta la documentación oficial para aprovecharlas al máximo.
Soporte#
Si encuentras problemas o tienes preguntas acerca de las aplicaciones interactivas en Open OnDemand, no dudes en ponerte en contacto con nosotros a través del correo electrónico support@hpc.iter.es. Estamos aquí para ayudarte.
Ended: OnDemand
Ended: Servicios
Preguntas frecuentes.#
Si tienes algúna preguntanos en support@hpc.iter.es